論文サーベイ:Singing Voice Conversion(歌声変換)
目次
- 目次
- 本記事の概要
- Unsupervised Singing Voice Conversion
- PitchNet: Unsupervised Singing Voice Conversion with Pitch Adversarial Network
- Unsupervised Cross-Domain Singing Voice Conversion
- FastSVC: Fast Cross-Domain Singing Voice Conversion with Feature-wise Linear Modulation
- PPG-BASED SINGING VOICE CONVERSION WITH ADVERSARIAL REPRESENTATION LEARNING
- Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
- サーベイのまとめ
- 参考文献
本記事の概要
歌声変換(Singing Voice Conversion, SVC)に関する論文のサーベイを行ったので、内容をまとめておきます。
歌声変換とは、歌手Aの歌声音声を歌手Bの歌声音声へと変換するタスクを指します。
音声変換にとても良く似たタスクですが、対象とする音声が一般的な話し声の音声ではなく歌声の音声である点が特徴です。
歌声を扱うモデルが、歌声に含まれる「音程」の情報をどのように扱っているのか知りたかったので、2019~2021年(現在まで)の手法を網羅的に調査しました。
以下、発表時点での品質が良い手法、筋の良さそうな手法をまとめています。
Unsupervised Singing Voice Conversion
概要
arxiv:https://arxiv.org/abs/1904.06590
demo : https://enk100.github.io/Unsupervised_Singing_Voice_Conversion/
本手法では、歌声変換を行うための深層学習手法を提案しています。
提案しているアーキテクチャは、テキストや音程などの追加の情報を与えることなく、ある歌手の音声を別の話者の音声へと変換することを可能とします。
また、比較的小さなデータセットを用いた学習を行う必要があるため、逆翻訳(backtranslation)に基づく新たな学習データ増強スキームを提案しています。
MOS評価の結果、提案手法による変換は話者類似性や自然性において高い評価を獲得しました。
詳細
本手法で提案しているモデルのアーキテクチャです。
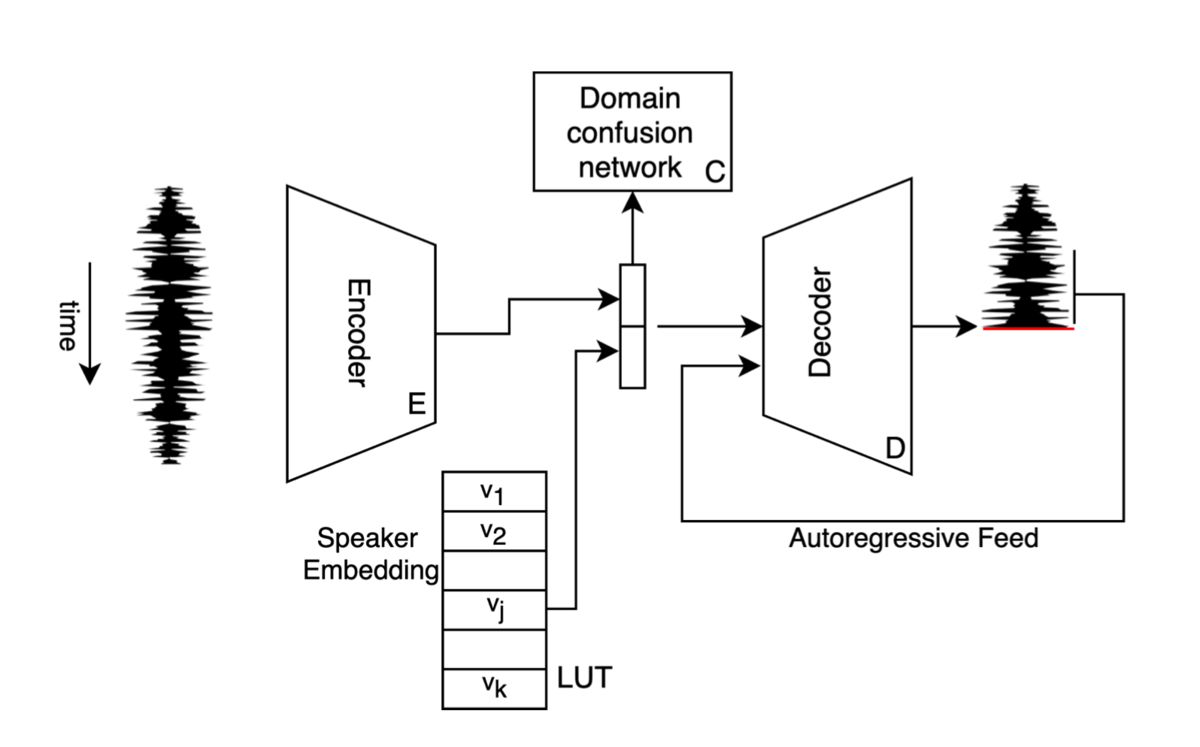
Decoder:Encoder から与えられる情報と話者埋め込みベクトルをもとに、目標話者の音声を生成するモデルです。
Domain confusion network:Encoder により圧縮された情報から、入力話者を推論するモデルです。 Encoder は、Domain confusion network を騙せるように学習を行います。
本手法では、2段階の学習プロセスを行います。

(a) 第一段階の学習では、入力として与える話者jの音声を Encoder により特徴空間に圧縮し、そこから Decoder によりもう一度同一話者の音声
へと復元するという学習を行います。
ここで、 Decoder には 話者jの埋め込みベクトルが同時に与えられます。
(b) 第一段階の学習だけでは、入力として与えられる話者は教師データの規模に左右されてしまします。そこで、第二段階の学習では、 mixup によるデータ増強手法を用いることで、多様な入力話者を生成し、学習に用いています。
本手法の mixup によるデータ増強では、3epochごとにオリジナルの話者を生成するプロセスを実行します(図の黒枠で囲まれている部分です)。話者jと話者j’のそれぞれの話者埋め込みベクトルと
を
(論文では
を作成し、その新たな話者埋め込みベクトルを用いて、話者jの音声から教師データに存在しない新たな話者の音声を生成します。
上記のプロセスにより教師データ外の話者のパラレルデータを作成することで、生成した新たな話者の音声を入力とし、元々の話者jの音声へと変換を行うという異なる話者間における音声変換の学習が可能となり、かつ入力に対する頑健性を高めることができます。
また本手法では、mixupの他に以下のアプローチによって教師データの増強を行っています。
逆翻訳(backtranslation)に基づくデータ増強
逆翻訳は、翻訳タスクで良くみられる手法で、言語Aの文章を言語Bへと翻訳するタスクを学習する際、学習中(もしくは学習済)モデルにより言語Bの文章を言語Aへと翻訳し、学習に使用する教師データを増やすというような手法です。inversion
音声波形は、波形を上下に反転させても知覚的には問題なく聞こえるということが知られています。本手法ではこの性質を利用し、wavに-1を掛けることでデータの水増しを行っています。
データセット
Smule DAMP Dataset : https://ccrma.stanford.edu/damp
- 学習に用いた音声:男性話者5人×9音声
- 評価に用いた音声:男性話者5人×1音声
PitchNet: Unsupervised Singing Voice Conversion with Pitch Adversarial Network
概要
arxiv:https://arxiv.org/abs/1912.01852
demo : https://tencent-ailab.github.io/pitch-net/
上記で紹介した「Unsupervised Singing Voice Conversion」を改良した手法です。
詳細
アーキテクチャや使用しているデータセットはUnsupervised Singing Voice Conversionとほぼ同じなので割愛します。ここでは、本手法の新規性であるPitchNet部分にフォーカスして解説しようと思います。
以下は、本手法が提案する音声変換のフローを表す図になります。
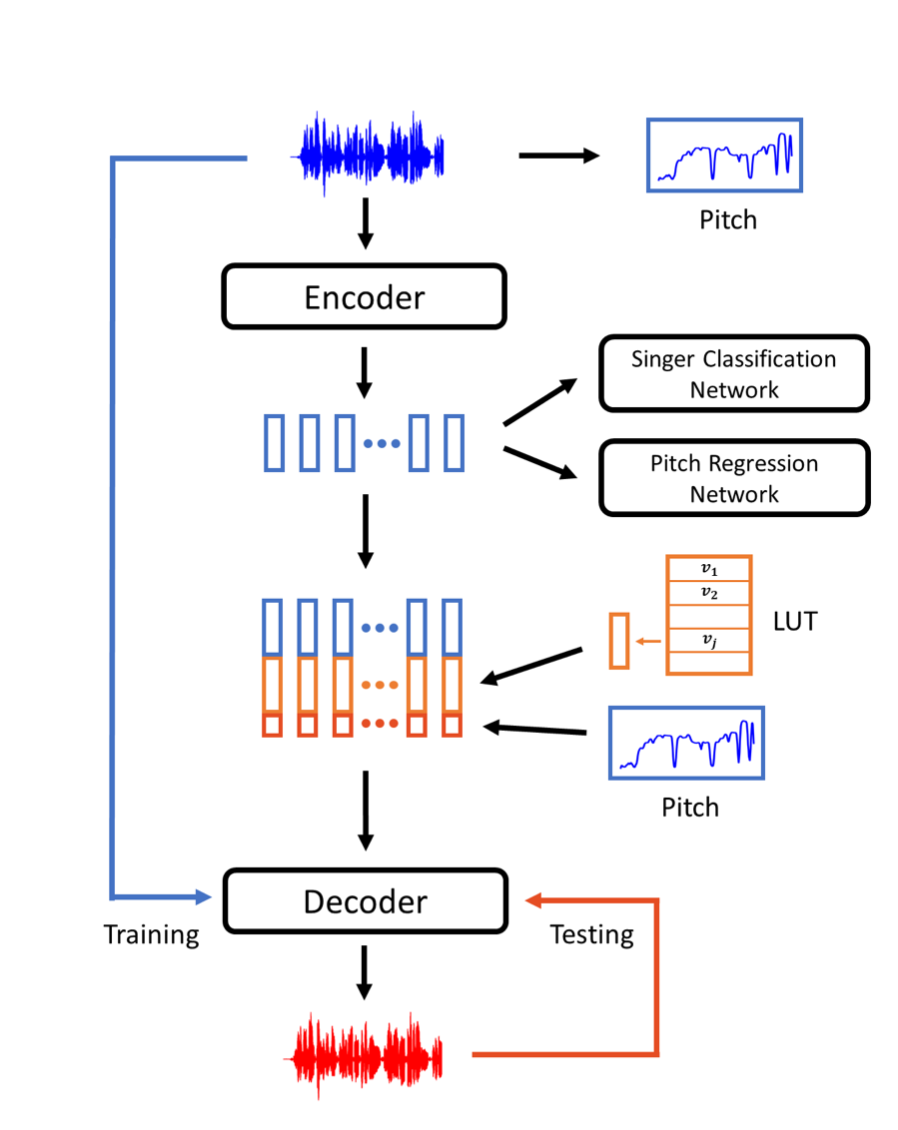
- 入力音声からPitchNetを用いてPitch情報を推論
- Encoderにより圧縮された特徴空間に対して、話者の識別を行うNetworkと、Pitch情報を推論するNetwork(PitchNet)を学習
- Encoderはこれらの学習を阻害できるように学習を行います。これにより、Encoderは入力音声から、話者に関する情報とPitchに関する情報以外の情報を圧縮するようになります
- Decoderは、Encoderから得られた情報に加えて、入力音声から推論したPitch情報と話者埋め込みベクトルを用いて音声を生成
データセット
NUS-48E
- 学習に用いた音声:男性話者5人×4音声
- 評価に用いた音声:男性話者1人×4音声
Unsupervised Cross-Domain Singing Voice Conversion
概要
arxiv:https://arxiv.org/abs/2008.028302
demo : https://singing-conversion.github.io/
Parallel WaveGANをベースとした、wav-to-wavの歌声変換手法を提案。
詳細
近年の研究で、歌声の変換には言語的情報と音楽的情報の両方が必要であることがわかってきています。
この手法では、言語的情報として、word2letterにより得られた情報を、音楽的情報として音の大きさとF0の情報を与えることで、変換の品質を向上させました。

予備実験において、生のF0を入力として与えた場合、生成される音声のピッチに一貫性のない揺れが生じることを確認しました。そのため、入力音声からCREPEという手法を用いて得られたPitch情報を元にSin波を合成し、波形データとしてPitch情報をモデルに与えるというアプローチを取っています。(数式についてはこの次に紹介する手法で取り扱っています)
CREPE
[1802.06182] CREPE: A Convolutional Representation for Pitch Estimation
CREPE Interactive Demo
ASRモデルにはJasperというWav2Letterの公開実装モデルを用いています。
(FacebookのAI Researchチームによる論文なので、Facebook製の手法が多く採用されています)
Jasper
[1904.03288] Jasper: An End-to-End Convolutional Neural Acoustic Model
[1609.03193] Wav2Letter: an End-to-End ConvNet-based Speech Recognition System
データセット
- LJ
single singer
24 hours of audio recording. - LCSING
single singer
3 hours and 40 minutes, including some melodic singing without lyrics. - VCTK
109 singers
44 hours of audio recordings - NUS-48E
six male singers and six female singers singing and reading of four songs per voice, 15 minutes per singer.
FastSVC: Fast Cross-Domain Singing Voice Conversion with Feature-wise Linear Modulation
概要
arxiv:https://arxiv.org/abs/2011.05731
demo : https://nobody996.github.io/FastSVC/
上記のUnsupervised Cross-Domain Singing Voice Conversionという手法では、3つの重い深層学習モデルを使用している(CREPE: f0 prediction, Jasper: wave-to-letter model, WaveNet based generator: vocoder)が、これは推論時間を非常に遅くする要因となっています。
また、学習手法が複雑であり、かつ時間がかかってしまいます。
提案手法であるFastSVCでは上記を改善し、軽量で、同様の品質を保ちつつ、CPU上でリアルタイムの4倍高速に変換が可能としています。
詳細
FastSVCのContributionとしては、以下が挙げられます。
- cross domainの学習が可能
- any-to-manyの歌声変換を実現
- Conformerと呼ばれる、軽量なend-to-end ASR モデルと、FiLMと呼ばれるGANベースの生成モデルを採用することで高速な推論を実現
- Multi-scale STFT lossとAdversarial lossの2つのLossのみで学習するため、シンプルかつ高速なLoss計算が可能
[2005.08100] Conformer: Convolution-augmented Transformer for Speech Recognition
[1709.07871] FiLM: Visual Reasoning with a General Conditioning Layer

- loudness features
波形のパワースペクトラムから算出される、音声のボリュームの特徴量 - linguistic features
ASRモデルから得られる言語特徴表現
学習済のConformerのモデルから、CTC moduleとattention decoderを切り捨てた残りの部分で推論したアウトプットを利用する - sine-excitation signal
Unsupervised Cross-Domain Singing Voice Conversionでも用いられていた手法で、入力音声から得られたPitch情報を元にSin波を合成し、波形としてPitch情報を表現するアプローチ。以下の数式により与えられる。

データセット
- LJ-Speech corpus
- VCTK corpus
- NUS-48E corpus
Datasets are randomly split into train-validation-test sets according to a 90%-5%-5% partition.
PPG-BASED SINGING VOICE CONVERSION WITH ADVERSARIAL REPRESENTATION LEARNING
概要
arxiv:https://arxiv.org/abs/2010.14804
demo : https://lzh1.github.io/singVC/
AutoEncoderベースの手法は、入力音声に含まれるノイズにより、品質が低下してしまうことが問題でした。
また、PitchNetは男性から男性への変換にしか対応していませんでした。
本手法では、上記の問題を解決する、end-to-endでの学習が可能なmany-to-manyのSVCモデルを提案しています。
詳細
本手法の特徴的な点として、PPG-to-Melのアプローチを取っているところがあります。

WaveNetベースやMelGANベースの手法が多いので、以外とPPG→MelSpectrogramでVocoderを用いて生成する手法は珍しいかもしれないです。
別途Vocoderを用意する必要はありますが、学習を別々に行える、タスクを分離できるというのはメリットかもしれません。
データセット
- internal Chinese mandarin singing corpus
32.7 hour audio data
9 female singers and 7 male singers
Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
概要
arxiv:[2012.01837] Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
demo : https://hhguo.github.io/DemoEASVC/
本論文では、end-to-endの敵対的歌声変換手法であるEA-SVC(End-to-end Adversarial Singing Voice Conversion)を提案しています。
EA-SVCでは、発生内容を表すPPG(phonetic posterior-gram、音素事後確率)、ピッチを表すF0、音色を表す話者埋め込みの3種類の特徴量から任意の歌声音声波形を直接生成することが可能です。
提案するモデルは、Generator 、Audio Generation Discriminator
、Feature Disentanglement Discriminator
の3つのモジュールから構成されています。
Generator
は入力される3種類の特徴量を並列にエンコードし、それらをconcatした物をデコードすることで目的の波形へと変換します。
さらに、Feature Disentanglement Discriminator
を適用し、Generator
によりエンコードされたPPGに残っているPitchとtimbrerの情報を除去することで、よりロバストで正確な歌声変換を実現することが可能となります。
また、提案手法では訓練を2段階に分けて行っており、これにより安定した効果的な敵対者訓練プロセスを維持することが可能となります。
実験より、提案モデルは品質と話者類似性の両方において従来のcascadeな畳み込みの手法とWaveNetベースのend-to-endの手法を凌駕していることが確認できました。
また客観分析では、提案する2段階の訓練により学習したモデルはより滑らかでシャープなフォルマントを生成し、高品質化な生成が可能になることが明らかになりました。
詳細
本手法に関しては、以下の解説記事でより詳細に解説をしているので、本記事では解説は行いません。
解説記事:https://aria3366.hatenablog.com/entry/2020/12/17/112800
サーベイのまとめ
2019年はAutoEncoderベースの手法が多かったように思います。Non-Parallelな教師データを用いた学習手法に関する注目度が上がったことが原因のようです。品質に関しては、非常に小さな学習データにもかかわらず、歌声の変換が出来ているように感じました。しかし、ピッチに関してはまだまだ変換が甘い箇所があったり、ノイズっぽい音が混じっていたので、完璧とは言えない品質ではありました。また、demoが全てMale→Maleなのも気になりました。
2020年以降は、PPGベースの手法が増えてきていました。AutoEncoderベースでは、ピッチに関する情報をうまく扱えないとわかってきたので、音韻の情報(PPG)とピッチの情報を別々に処理するアプローチが主流になったようです。 PPGベースの手法の場合、decoderが音声を生成する際にpitchの情報を外部から与える必要があるため、pitchが大きく異なる場合にも対応出来そうな感じがします。 実際、PPGベースの手法は、demoにおいて異性間の歌声音声が上手く変換出来ているように感じました。 また、PPGベースの手法では、音素認識部分の学習に歌声コーパス以外の教師データを使用することができるので、より学習の難易度が下がるというメリットもありそうです。
また最近では、FastSVCのような高速化を目指した手法もあるようです。 実用化に向けた研究も始まってきているようですね。
サーベイをしていて感じたのですが、2020年〜2021年にかけて、Neural Vocoderに関する手法が沢山発表されていました。今までだと、(Parallel) WaveNet, WaveGlow, WaveFlow, WaveRNN, (Parallel) WaveGAN, MelGAN, Multi-Band Melgan, LPCNetのような手法が使われていたと思うのですが、さらに進化してきているのでしょうか...Vocoderに関してもサーベイを行った方が良いかもしれないです。
*1*2*3*4*5*6*7*8
また、もう一つ感じたのが、中国の大学・企業の論文が非常に多いという点でした。
(VCも多いですが)SVCの分野における中国の大学・企業の論文の割合は、体感で8割以上はありそうでした。
日本発の論文ももっと増やして行きたいですね...。