論文サーベイ:Singing Voice Conversion(歌声変換)
目次
- 目次
- 本記事の概要
- Unsupervised Singing Voice Conversion
- PitchNet: Unsupervised Singing Voice Conversion with Pitch Adversarial Network
- Unsupervised Cross-Domain Singing Voice Conversion
- FastSVC: Fast Cross-Domain Singing Voice Conversion with Feature-wise Linear Modulation
- PPG-BASED SINGING VOICE CONVERSION WITH ADVERSARIAL REPRESENTATION LEARNING
- Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
- サーベイのまとめ
- 参考文献
本記事の概要
歌声変換(Singing Voice Conversion, SVC)に関する論文のサーベイを行ったので、内容をまとめておきます。
歌声変換とは、歌手Aの歌声音声を歌手Bの歌声音声へと変換するタスクを指します。
音声変換にとても良く似たタスクですが、対象とする音声が一般的な話し声の音声ではなく歌声の音声である点が特徴です。
歌声を扱うモデルが、歌声に含まれる「音程」の情報をどのように扱っているのか知りたかったので、2019~2021年(現在まで)の手法を網羅的に調査しました。
以下、発表時点での品質が良い手法、筋の良さそうな手法をまとめています。
Unsupervised Singing Voice Conversion
概要
arxiv:https://arxiv.org/abs/1904.06590
demo : https://enk100.github.io/Unsupervised_Singing_Voice_Conversion/
本手法では、歌声変換を行うための深層学習手法を提案しています。
提案しているアーキテクチャは、テキストや音程などの追加の情報を与えることなく、ある歌手の音声を別の話者の音声へと変換することを可能とします。
また、比較的小さなデータセットを用いた学習を行う必要があるため、逆翻訳(backtranslation)に基づく新たな学習データ増強スキームを提案しています。
MOS評価の結果、提案手法による変換は話者類似性や自然性において高い評価を獲得しました。
詳細
本手法で提案しているモデルのアーキテクチャです。
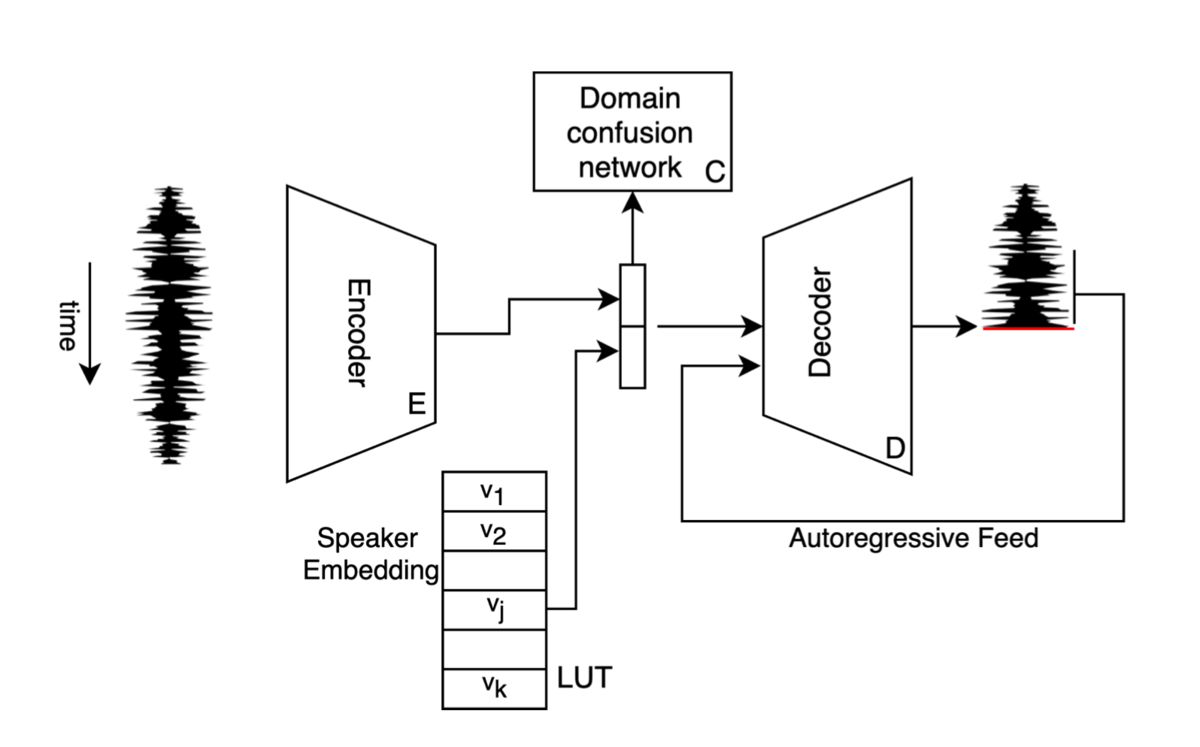
Decoder:Encoder から与えられる情報と話者埋め込みベクトルをもとに、目標話者の音声を生成するモデルです。
Domain confusion network:Encoder により圧縮された情報から、入力話者を推論するモデルです。 Encoder は、Domain confusion network を騙せるように学習を行います。
本手法では、2段階の学習プロセスを行います。

(a) 第一段階の学習では、入力として与える話者jの音声を Encoder により特徴空間に圧縮し、そこから Decoder によりもう一度同一話者の音声
へと復元するという学習を行います。
ここで、 Decoder には 話者jの埋め込みベクトルが同時に与えられます。
(b) 第一段階の学習だけでは、入力として与えられる話者は教師データの規模に左右されてしまします。そこで、第二段階の学習では、 mixup によるデータ増強手法を用いることで、多様な入力話者を生成し、学習に用いています。
本手法の mixup によるデータ増強では、3epochごとにオリジナルの話者を生成するプロセスを実行します(図の黒枠で囲まれている部分です)。話者jと話者j’のそれぞれの話者埋め込みベクトルと
を
(論文では
を作成し、その新たな話者埋め込みベクトルを用いて、話者jの音声から教師データに存在しない新たな話者の音声を生成します。
上記のプロセスにより教師データ外の話者のパラレルデータを作成することで、生成した新たな話者の音声を入力とし、元々の話者jの音声へと変換を行うという異なる話者間における音声変換の学習が可能となり、かつ入力に対する頑健性を高めることができます。
また本手法では、mixupの他に以下のアプローチによって教師データの増強を行っています。
逆翻訳(backtranslation)に基づくデータ増強
逆翻訳は、翻訳タスクで良くみられる手法で、言語Aの文章を言語Bへと翻訳するタスクを学習する際、学習中(もしくは学習済)モデルにより言語Bの文章を言語Aへと翻訳し、学習に使用する教師データを増やすというような手法です。inversion
音声波形は、波形を上下に反転させても知覚的には問題なく聞こえるということが知られています。本手法ではこの性質を利用し、wavに-1を掛けることでデータの水増しを行っています。
データセット
Smule DAMP Dataset : https://ccrma.stanford.edu/damp
- 学習に用いた音声:男性話者5人×9音声
- 評価に用いた音声:男性話者5人×1音声
PitchNet: Unsupervised Singing Voice Conversion with Pitch Adversarial Network
概要
arxiv:https://arxiv.org/abs/1912.01852
demo : https://tencent-ailab.github.io/pitch-net/
上記で紹介した「Unsupervised Singing Voice Conversion」を改良した手法です。
詳細
アーキテクチャや使用しているデータセットはUnsupervised Singing Voice Conversionとほぼ同じなので割愛します。ここでは、本手法の新規性であるPitchNet部分にフォーカスして解説しようと思います。
以下は、本手法が提案する音声変換のフローを表す図になります。
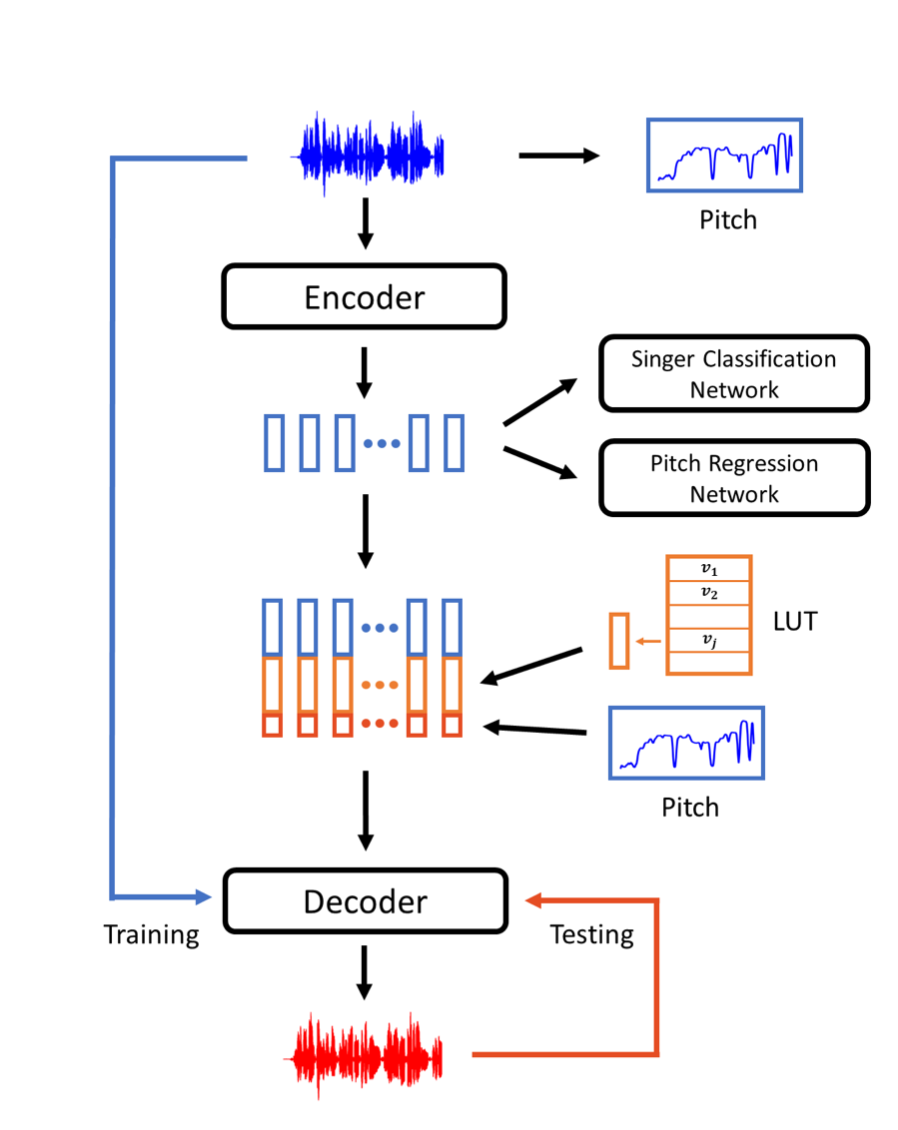
- 入力音声からPitchNetを用いてPitch情報を推論
- Encoderにより圧縮された特徴空間に対して、話者の識別を行うNetworkと、Pitch情報を推論するNetwork(PitchNet)を学習
- Encoderはこれらの学習を阻害できるように学習を行います。これにより、Encoderは入力音声から、話者に関する情報とPitchに関する情報以外の情報を圧縮するようになります
- Decoderは、Encoderから得られた情報に加えて、入力音声から推論したPitch情報と話者埋め込みベクトルを用いて音声を生成
データセット
NUS-48E
- 学習に用いた音声:男性話者5人×4音声
- 評価に用いた音声:男性話者1人×4音声
Unsupervised Cross-Domain Singing Voice Conversion
概要
arxiv:https://arxiv.org/abs/2008.028302
demo : https://singing-conversion.github.io/
Parallel WaveGANをベースとした、wav-to-wavの歌声変換手法を提案。
詳細
近年の研究で、歌声の変換には言語的情報と音楽的情報の両方が必要であることがわかってきています。
この手法では、言語的情報として、word2letterにより得られた情報を、音楽的情報として音の大きさとF0の情報を与えることで、変換の品質を向上させました。

予備実験において、生のF0を入力として与えた場合、生成される音声のピッチに一貫性のない揺れが生じることを確認しました。そのため、入力音声からCREPEという手法を用いて得られたPitch情報を元にSin波を合成し、波形データとしてPitch情報をモデルに与えるというアプローチを取っています。(数式についてはこの次に紹介する手法で取り扱っています)
CREPE
[1802.06182] CREPE: A Convolutional Representation for Pitch Estimation
CREPE Interactive Demo
ASRモデルにはJasperというWav2Letterの公開実装モデルを用いています。
(FacebookのAI Researchチームによる論文なので、Facebook製の手法が多く採用されています)
Jasper
[1904.03288] Jasper: An End-to-End Convolutional Neural Acoustic Model
[1609.03193] Wav2Letter: an End-to-End ConvNet-based Speech Recognition System
データセット
- LJ
single singer
24 hours of audio recording. - LCSING
single singer
3 hours and 40 minutes, including some melodic singing without lyrics. - VCTK
109 singers
44 hours of audio recordings - NUS-48E
six male singers and six female singers singing and reading of four songs per voice, 15 minutes per singer.
FastSVC: Fast Cross-Domain Singing Voice Conversion with Feature-wise Linear Modulation
概要
arxiv:https://arxiv.org/abs/2011.05731
demo : https://nobody996.github.io/FastSVC/
上記のUnsupervised Cross-Domain Singing Voice Conversionという手法では、3つの重い深層学習モデルを使用している(CREPE: f0 prediction, Jasper: wave-to-letter model, WaveNet based generator: vocoder)が、これは推論時間を非常に遅くする要因となっています。
また、学習手法が複雑であり、かつ時間がかかってしまいます。
提案手法であるFastSVCでは上記を改善し、軽量で、同様の品質を保ちつつ、CPU上でリアルタイムの4倍高速に変換が可能としています。
詳細
FastSVCのContributionとしては、以下が挙げられます。
- cross domainの学習が可能
- any-to-manyの歌声変換を実現
- Conformerと呼ばれる、軽量なend-to-end ASR モデルと、FiLMと呼ばれるGANベースの生成モデルを採用することで高速な推論を実現
- Multi-scale STFT lossとAdversarial lossの2つのLossのみで学習するため、シンプルかつ高速なLoss計算が可能
[2005.08100] Conformer: Convolution-augmented Transformer for Speech Recognition
[1709.07871] FiLM: Visual Reasoning with a General Conditioning Layer

- loudness features
波形のパワースペクトラムから算出される、音声のボリュームの特徴量 - linguistic features
ASRモデルから得られる言語特徴表現
学習済のConformerのモデルから、CTC moduleとattention decoderを切り捨てた残りの部分で推論したアウトプットを利用する - sine-excitation signal
Unsupervised Cross-Domain Singing Voice Conversionでも用いられていた手法で、入力音声から得られたPitch情報を元にSin波を合成し、波形としてPitch情報を表現するアプローチ。以下の数式により与えられる。

データセット
- LJ-Speech corpus
- VCTK corpus
- NUS-48E corpus
Datasets are randomly split into train-validation-test sets according to a 90%-5%-5% partition.
PPG-BASED SINGING VOICE CONVERSION WITH ADVERSARIAL REPRESENTATION LEARNING
概要
arxiv:https://arxiv.org/abs/2010.14804
demo : https://lzh1.github.io/singVC/
AutoEncoderベースの手法は、入力音声に含まれるノイズにより、品質が低下してしまうことが問題でした。
また、PitchNetは男性から男性への変換にしか対応していませんでした。
本手法では、上記の問題を解決する、end-to-endでの学習が可能なmany-to-manyのSVCモデルを提案しています。
詳細
本手法の特徴的な点として、PPG-to-Melのアプローチを取っているところがあります。

WaveNetベースやMelGANベースの手法が多いので、以外とPPG→MelSpectrogramでVocoderを用いて生成する手法は珍しいかもしれないです。
別途Vocoderを用意する必要はありますが、学習を別々に行える、タスクを分離できるというのはメリットかもしれません。
データセット
- internal Chinese mandarin singing corpus
32.7 hour audio data
9 female singers and 7 male singers
Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
概要
arxiv:[2012.01837] Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
demo : https://hhguo.github.io/DemoEASVC/
本論文では、end-to-endの敵対的歌声変換手法であるEA-SVC(End-to-end Adversarial Singing Voice Conversion)を提案しています。
EA-SVCでは、発生内容を表すPPG(phonetic posterior-gram、音素事後確率)、ピッチを表すF0、音色を表す話者埋め込みの3種類の特徴量から任意の歌声音声波形を直接生成することが可能です。
提案するモデルは、Generator 、Audio Generation Discriminator
、Feature Disentanglement Discriminator
の3つのモジュールから構成されています。
Generator
は入力される3種類の特徴量を並列にエンコードし、それらをconcatした物をデコードすることで目的の波形へと変換します。
さらに、Feature Disentanglement Discriminator
を適用し、Generator
によりエンコードされたPPGに残っているPitchとtimbrerの情報を除去することで、よりロバストで正確な歌声変換を実現することが可能となります。
また、提案手法では訓練を2段階に分けて行っており、これにより安定した効果的な敵対者訓練プロセスを維持することが可能となります。
実験より、提案モデルは品質と話者類似性の両方において従来のcascadeな畳み込みの手法とWaveNetベースのend-to-endの手法を凌駕していることが確認できました。
また客観分析では、提案する2段階の訓練により学習したモデルはより滑らかでシャープなフォルマントを生成し、高品質化な生成が可能になることが明らかになりました。
詳細
本手法に関しては、以下の解説記事でより詳細に解説をしているので、本記事では解説は行いません。
解説記事:https://aria3366.hatenablog.com/entry/2020/12/17/112800
サーベイのまとめ
2019年はAutoEncoderベースの手法が多かったように思います。Non-Parallelな教師データを用いた学習手法に関する注目度が上がったことが原因のようです。品質に関しては、非常に小さな学習データにもかかわらず、歌声の変換が出来ているように感じました。しかし、ピッチに関してはまだまだ変換が甘い箇所があったり、ノイズっぽい音が混じっていたので、完璧とは言えない品質ではありました。また、demoが全てMale→Maleなのも気になりました。
2020年以降は、PPGベースの手法が増えてきていました。AutoEncoderベースでは、ピッチに関する情報をうまく扱えないとわかってきたので、音韻の情報(PPG)とピッチの情報を別々に処理するアプローチが主流になったようです。 PPGベースの手法の場合、decoderが音声を生成する際にpitchの情報を外部から与える必要があるため、pitchが大きく異なる場合にも対応出来そうな感じがします。 実際、PPGベースの手法は、demoにおいて異性間の歌声音声が上手く変換出来ているように感じました。 また、PPGベースの手法では、音素認識部分の学習に歌声コーパス以外の教師データを使用することができるので、より学習の難易度が下がるというメリットもありそうです。
また最近では、FastSVCのような高速化を目指した手法もあるようです。 実用化に向けた研究も始まってきているようですね。
サーベイをしていて感じたのですが、2020年〜2021年にかけて、Neural Vocoderに関する手法が沢山発表されていました。今までだと、(Parallel) WaveNet, WaveGlow, WaveFlow, WaveRNN, (Parallel) WaveGAN, MelGAN, Multi-Band Melgan, LPCNetのような手法が使われていたと思うのですが、さらに進化してきているのでしょうか...Vocoderに関してもサーベイを行った方が良いかもしれないです。
*1*2*3*4*5*6*7*8
また、もう一つ感じたのが、中国の大学・企業の論文が非常に多いという点でした。
(VCも多いですが)SVCの分野における中国の大学・企業の論文の割合は、体感で8割以上はありそうでした。
日本発の論文ももっと増やして行きたいですね...。
参考文献
論文解説:Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
目次
論文情報
arxiv:[2012.01837] Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
demo : https://hhguo.github.io/DemoEASVC/
概要
本論文では、end-to-endの敵対的歌声変換手法であるEA-SVC(End-to-end Adversarial Singing Voice Conversion)を提案しています。
EA-SVCでは、発生内容を表すPPG(phonetic posterior-gram、音素事後確率)、ピッチを表すF0、音色を表す話者埋め込みの3種類の特徴量から任意の歌声音声波形を直接生成することが可能です。
提案するモデルは、Generator 、Audio Generation Discriminator
、Feature Disentanglement Discriminator
の3つのモジュールから構成されています。
Generator
は入力される3種類の特徴量を並列にエンコードし、それらをconcatした物をデコードすることで目的の波形へと変換します。
さらに、Feature Disentanglement Discriminator
を適用し、Generator
によりエンコードされたPPGに残っているPitchとtimbrerの情報を除去することで、よりロバストで正確な歌声変換を実現することが可能となります。
また、提案手法では訓練を2段階に分けて行っており、これにより安定した効果的な敵対者訓練プロセスを維持することが可能となります。
実験より、提案モデルは品質と話者類似性の両方において従来のcascadeな畳み込みの手法とWaveNetベースのend-to-endの手法を凌駕していることが確認できました。
また客観分析では、提案する2段階の訓練により学習したモデルはより滑らかでシャープなフォルマントを生成し、高品質化な生成が可能になることが明らかになりました。
提案手法
本論文では、end-to-endの敵対的歌声変換手法であるEA-SVCを提案しています。
本論文のContributionsとして、以下のことが挙げられます。
波形にPPG、F0、話者埋め込みをマッピングするために、MelGAN[2]をベースにしたジェネレータを設計しています。
入力特徴量を波形に変換する際に、CNN-BLSTMベースのモジュールにより、PPGとF0シーケンスからそれぞれの特徴量を抽出し、concatしています。 また、ロバストで制御可能な音色表現を獲得するため、話者埋め込みは異なる音色・話者を表す訓練可能なベクトルの重み付け和として表現されます。2つの識別器がGenerator
の学習プロセスに追加されます。
Audio Generation Discriminatorは、本物の音声と生成された偽の音声を分類することで、より良い品質の音声を生成できるようにGenerator
はエンコードされたPPGの情報からピッチ情報と音色情報を推測するような学習を行い、Generator
上記学習プロセスを効率的かつ安定的に行うために、2段階の学習戦略を採用しています。
提案手法では、まずmulti-resolution STFT(MR-STFT) Lossを用いて生成器を訓練し、その後モデルをより安定させるためにMR-STFT Lossと敵対的Lossの両方を用いてモデルを訓練します。手法の評価のために、主観試験と実験分析を実施しています。
MOSによる評価の結果、提案手法の有効性が実証されました。 提案手法は従来のcascadeな畳み込みの手法やWaveNetベースのend-to-endの手法に比べて品質と話者類似度の両方において優れた性能を示したました。 客観分析では、提案する2段階の訓練により学習したモデルはより滑らかでシャープなフォルマントを生成し、高品質化な生成が可能になることが明らかになりました。 さらに、提案手法の有効性を検証するために、提案モデルを用いて音色やピッチの制御実験を行いました。
Generator
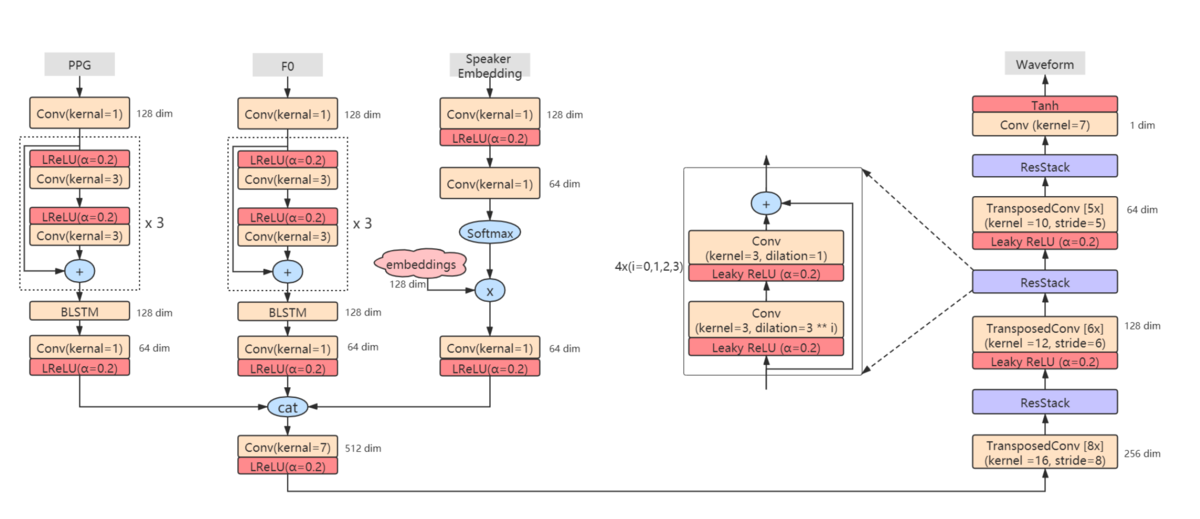
のアーキテクチャ
は、上記の概要図の左側と右側でそれぞれ別の役割を持っています。
図の左側のモジュールはEncoderとしての役割を担っています。入力としてPPG、F0、話者埋め込みベクトルのsequentialな情報を受け取り、並行して情報の圧縮を行います。
ここで、より良い話者埋め込み表現を獲得するため、GST-Tacotron[3]で提案された話者埋め込み手法にinspiredされた話者埋め込みのモジュールを提案しています。 以下が提案している話者埋め込みのモジュールを表す式となります。
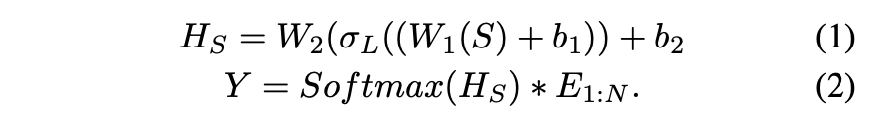
は非線形変換がなされた入力話者ベクトルを、
はtrainable weight vectorを表しています。
直接 を用いるのではなく、
を用いて
のweightを学習することで、clusteringもしくはdisentanglementを促すことができるという主張です。(詳細に関しては自分もまだ理解出来ていません)
図の右側のモジュールはUpsamplerとしての役割を担っています。Encoderにより圧縮された特徴量から、音声波形を直接生成します。
Upsamplerモジュールの構造はMelGAN[2]に非常によく似ており、またLossに関してもMelGANと同じmulti-resolution STFT Loss を用いています。
以下はSTFT Lossの定義を示す式となります。
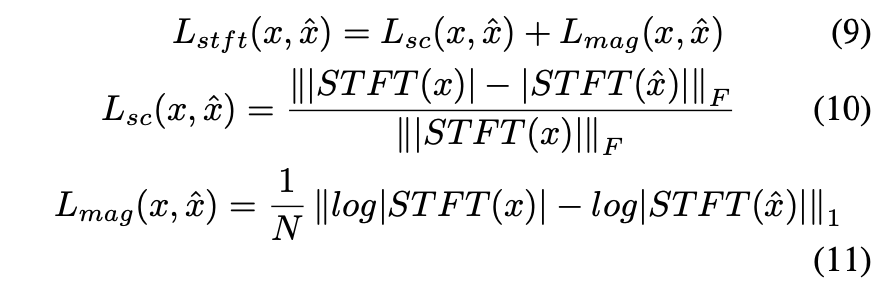
はspectral convergence Loss、
はlog STFT magnitude Lossを表し、それぞれスペクトル領域での周波数の割合と大きさについての差分を計算するようなLossとなっています。
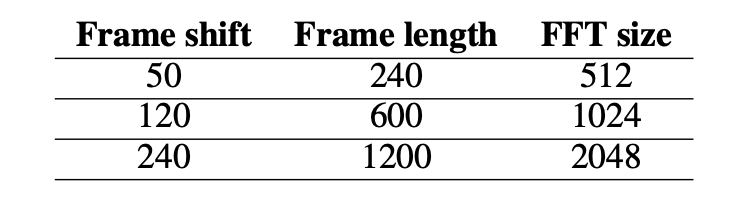
multi-resolution STFT Loss では、STFT Lossを複数の解像度で計算し、そのsumをとることで計算されます。論文では以下の表のパラメタを用いています。
後述する と
からのadversarial lossと上記をまとめると、
に対するLossは以下のようになります。
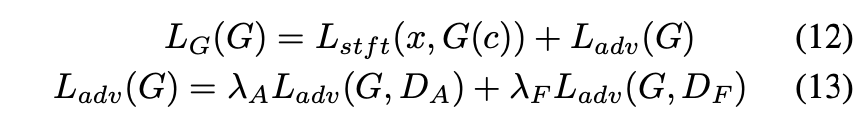
Audio Generation Discriminator

のアーキテクチャ
は、入力された音声がオリジナルの音声なのか、Generator
により生成された音声なのかを識別するような学習を行います。
を騙せるように
の学習を行うことで、
の生成する音声の品質を高めるのが狙いです。
に対するLossは以下のようになります。
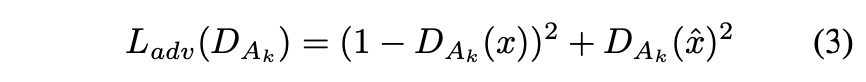
に対しては、通常のAdversarial Lossに加えて、以下の式で定義されるFeature Mapping Loss
を与えます。
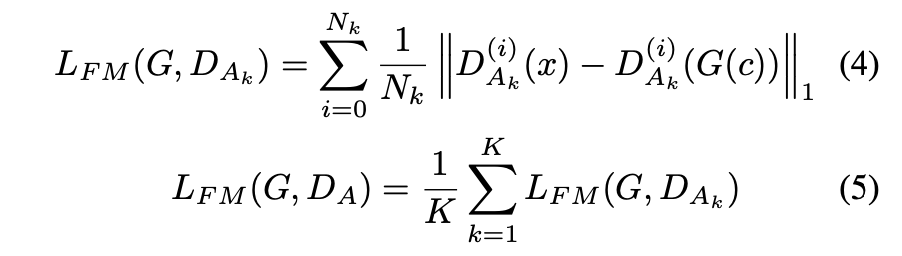
はオリジナルの音声が入力された場合と
により生成された音声が入力された際に、
のブロック
ごとの出力が同じになるような制約を
に与えています。この制約により、
が
の各特徴空間レベルでオリジナルの音声に似ている音声を生成できるように促します。
最終的に により与えられる
に対するLossは以下のようになります。
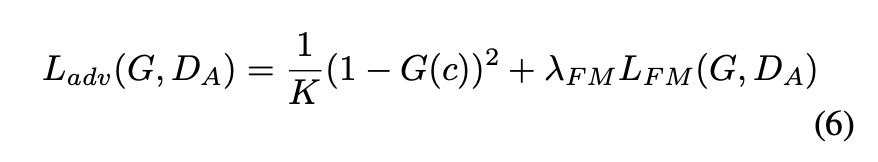
Feature Disentanglement Discriminator
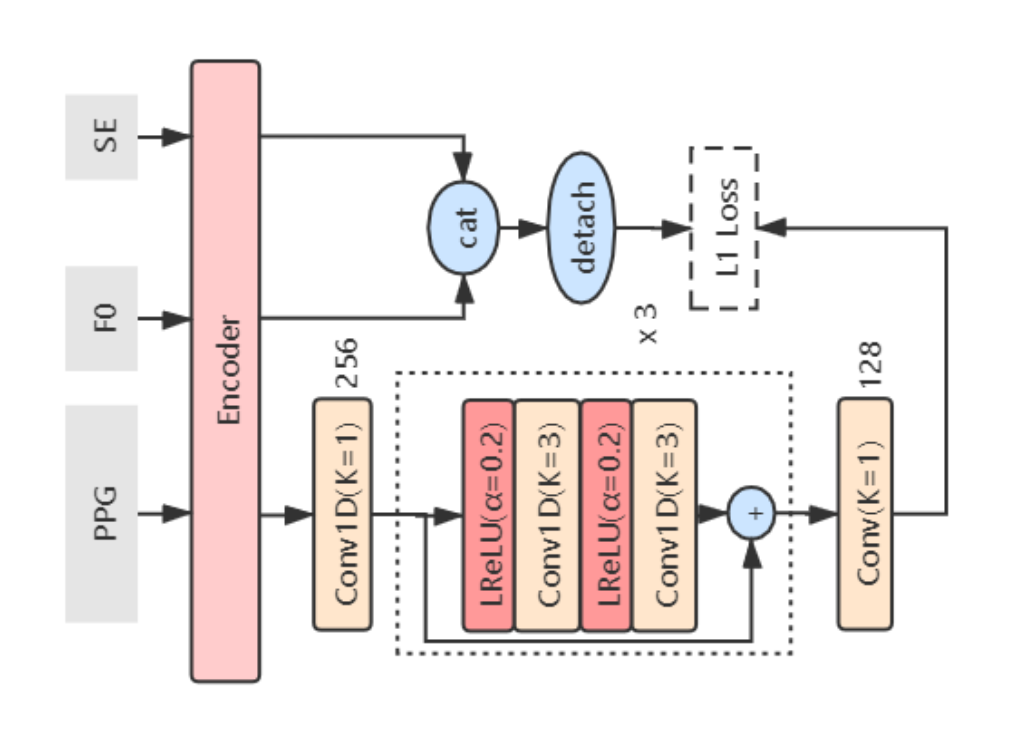
のアーキテクチャ
は、敵対的学習によりGenerator
によりエンコードされたPPGからF0と話者性に関する情報を除去するためのモジュールです。
PPGはコンテンツ情報をよく表現する一方で、音程や話者性の情報を含んでしまうことが知られており、モデルがその情報に依存してしまうと情報の衝突が発生しノイズの原因となってしまいます。
は、Generator
によりエンコードされたPPGから、同じくエンコードされたF0と話者埋め込み情報がconcatされた値を予測するように学習を行い、
にはそれを妨げるように制約を与えます。
ここで、 に対するLossは以下のようになります。
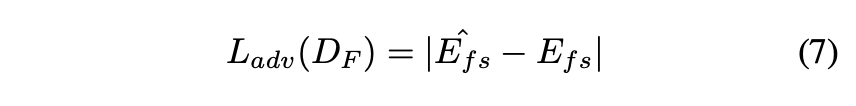
また、 を用いた
に対するLossは以下のようになります。
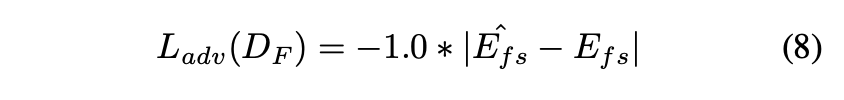
2段階の訓練
Generator 、Audio Generation Discriminator
、Feature Disentanglement Discriminator
の3つのモジュールを効率的に、安定して学習させるために、提案手法では学習を2つの段階に分けて行うアプローチを提案しています。
Stage 1では、 のみを学習させます。Lossは
のみを用います。
ここでの目的は、 が学習により入力特徴量と音声波形間の正確で安定したマッピングを獲得することです。これにより、
により安定した生成が行われることが保証されます。
Stage 2では、 、
、
の全てのモジュールを学習させます。Lossは全て用います。
ここでの目的は、Stage 1で学習した
のweightを、より最適な分布へと近づけることです。
実験
実験では、従来のcascadeアプローチの手法・WaveNetベースの手法と提案手法のMOS比較を行っています。
cascadeアプローチには、EA-SVCににたモデルを用意しています。違いとして、f0やspk_embを用いていないこと、生成対象がメルスペクトログラムであることが挙げられます。生成されたメルスペクトログラムは、学習済のMelGANを用いて音声波形へと変換します。
WaveNetベースのアプローチには、NVIDIAが以下のリポジトリで公開しているend-to-endの歌声変換モデルを用いています。
GitHub - NVIDIA/nv-wavenet: Reference implementation of real-time autoregressive wavenet inference
また、 、
の効果を検証するための
と
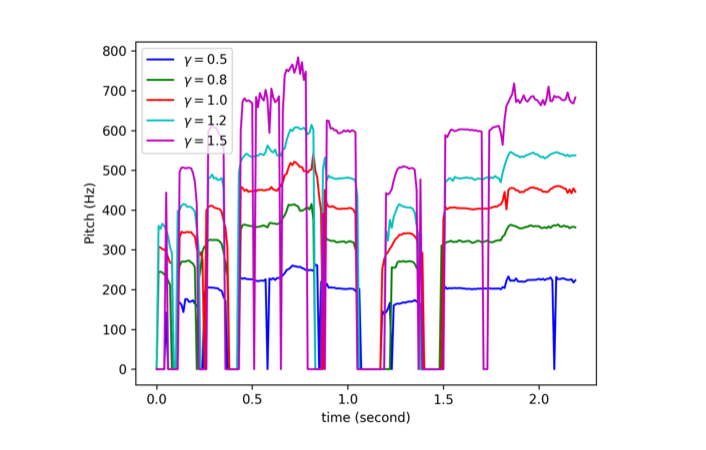
の有無による生成音声の比較実験、2段階の訓練を行う事による生成音声の比較実験、生成音声の制御性検証のためのピッチコントロール・話者性のコントロール実験についても追加で行っています。
結果
以下は、作者が公開している本手法のデモ音声が聴けるサイトです。
demo : https://hhguo.github.io/DemoEASVC/
以下は従来のcascadeアプローチの手法・WaveNetベースの手法と提案手法のMOS比較の結果を示す表になります。
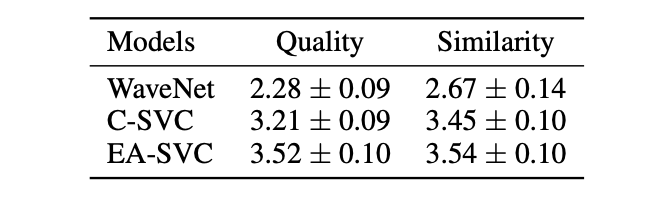
提案手法のMOSが優れていることが確認出来ます。
以下は、 と
の有無による品質と話者類似性の比較実験の結果を示す表になります。
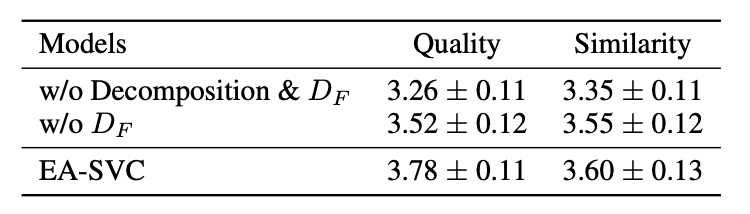
と
の有無による比較実験の結果
と
が品質に強く影響を与えていることが確認出来ます。
以下は2段階の訓練を行うことで、生成される音声のスペクトログラムにどのような差が生じるかの検証実験の結果を示す図になります。
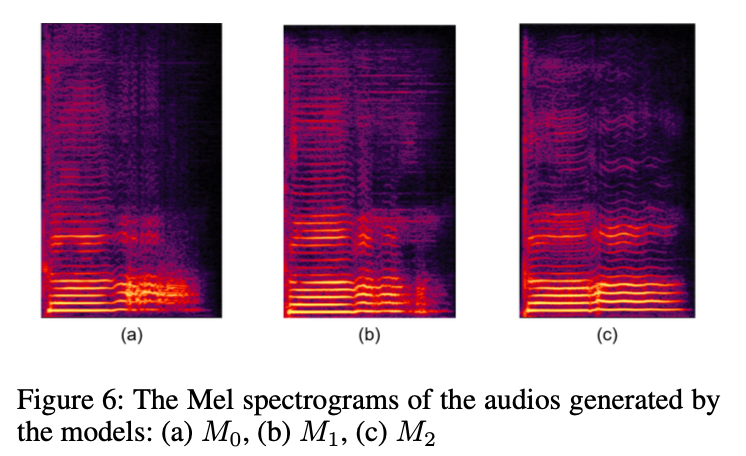
、
、
はそれぞれ以下のような設定で学習したものになります。
:Stage2のみの学習、
のみで学習。
:Stage2のみの学習、
)で学習
:Stage1+Stage2を段階的に学習、
がもっとも明瞭で滑らかなスペクトログラムであることが確認出来ます。
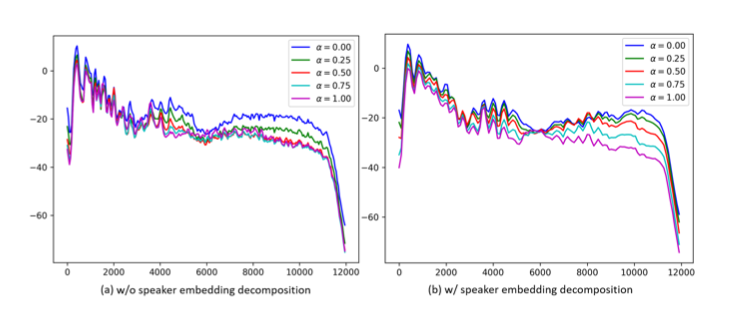
以下は、話者性を逐次的に変化させて行った際のaveraged magnitude spectrogramを示した図になります。
所感
最近の音声変換手法はPPGを使うアプローチが頭ひとつ抜けて品質が良い印象があります。
また、MelGAN[2]は学習が安定すること、生成音声の品質が良いこと、推論が従来のNeuralVocoderと比較して早いことなどから個人的に好きな手法だったので、MelGANのアーキテクチャをベースにしたEA-SVCのモデルアーキテクチャはかなり良いなと思いました。
参考文献
論文解説:Transfer Learning from Speech Synthesis to Voice Conversion with Non-Parallel Training Data
目次
論文情報
arxiv:[2009.14399] Transfer Learning from Speech Synthesis to Voice Conversion with Non-Parallel Training Data
demo : https://arkhamimp.github.io/TTL-VC/
概要
本論文では、Text-to-Speech(TTS)タスクで学習したモデルをVoice Conversion(VC)タスクへと転用する新たな学習フレームワーク(TTS-VC transfer learning、以下TTL-VC)を提案しています。
提案手法では始めに、seq2seqのEncoder-Decoder型マルチ話者音声合成モデル(Tacotron2)を学習します。
TTSタスクを学習することで、TTS Encoderは入力テキストからロバストな言語表現を抽出し、TTS Decoderは目標話者の話者埋め込み、Attention Context Vector、Attention Recurrent Network Cellの出力を用いて、目標話者の音響特徴(MelSpectrogram)を生成するようになります。
ここで、TTSタスクを学習したEncoderは、入力テキストから話者に依存しない文脈情報であるContext Vectorへのマッピングを学習をしていると考えることができます。
提案手法では、このマッピングをEncoder-Decoder型音声変換モデルの潜在表現に対して制約として加えるというアプローチをしています。
このアプローチにより、Encoderが音声から話者性を排除した埋め込み表現を獲得するように促します。
また、提案手法ではDecoderは目標話者のEmbeddingを用いて学習するので、Non-Parallelな教師データを用いた学習・任意の話者への音声変換を行うことが可能となります。
実験では、提案手法により得られた音声変換モデルが、品質、自然さ、話者類似性において、異なる2つの音声変換ベースライン手法(PPGベース、VAEベース)よりも優れていることを示し、さらにTTSモデルと同等品質の音声を生成できることを示しました。
提案手法
本論文では、Text-to-Speechタスクで学習したモデルをVoice Conversionタスクへと転用する新たな学習フレームワークであるTTL-VCを提案しています。
TTL-VCでは、事前に学習したTTSモデルの重みをVCタスクを学習するモデルの初期値として用いることで、以下の点で恩恵を得ています。
- Encoderの学習時にContext Vector(文脈情報ベクトル)による制約を用いることで、Encoderが音声から話者性に関する情報を完全に排除した埋め込み表現を獲得することが可能となる。
- 比較的収集しやすいTTSコーパスを用いて(Non-Parallelなコーパスで)VCタスクを学習することができる。
以下は、既存のTTSベースの手法(TTSタスクの知識を用いてVCタスクを学習する手法)と提案手法の学習の条件や制約について比較をした表です。

[41]:Cotatron: Transcription-guided speech encoder for any-to-many voice conversion without parallel data
[42]:Bootstrapping non-parallel voice conver- sion from speaker-adaptive text-to-speech
[43]:Joint training framework for text-to-speech and voice conversion using multi-Source Tacotron and WaveNet
[44]:Voice transformer network: Sequence-to-sequence voice conversion
using transformer with text-to-speech pretraining
TTL-VCでは、VCタスク向けの追加のデータ(音声のパラレルデータなど)を用意する必要がないという点が他の手法との大きな違いとなっています。
TTL-VC の概要

本論文で提案しているTTL-VCの概要図です。
図の上半分はTTSタスクの事前学習の概要を表しており、下半分がVCタスクの学習の概要を表しています。
TTSタスクによる事前学習
TTL-VCでは、事前学習としてTacotron2を用いてTTSタスクを学習します。以下は、Tacotron2のアーキテクチャの概要図です。

は入力としてテキスト列
を受け取り、テキスト埋め込みベクトル
を出力します。

と目標音響特徴
間のアラインメントを重み行列
として得ることができます。
テキスト埋め込みベクトル
に重み行列
を掛け合わせることで、Context Vector
を作成します。

には、生成するMelSpectrogramの各フレームに対応した言語情報が埋め込まれていると考えることができます。
Decoderの入力は、上記により生成されたContext Vector と話者埋め込みベクトル
をconcatした物になります。

は目標話者の音声から生成されたMelSpectrogram
と生成されたMelSpectrogram
のMSEにより計算されます。

TTL-VC の学習
VCタスクの学習では、Encoder-Decoder型のモデルを用いて学習を行います。Decoderの重みの初期値として、事前に学習したTTSモデルのDecoderの重みを用います。
は入力として音響特徴列
を受け取り、Context Vector
を出力します。

が事前に学習したTTSモデルにより生成されたContext Vector
に近付くように、以下のような制約
を加えます。

によりEncoderで話者性に関する情報が排除されると考えられるため、学習時に入力話者と目標話者を同一話者としても、Decoderが話者性を埋め込むような学習が促されると考えられます。
Decoderの入力は、TTSタスクの時と同様、Encoderにより生成されたContext Vector と話者埋め込みベクトル
がconcatされた物になります。

と
を足し合わせた物となります。

話者埋め込みベクトル は事前に学習された話者埋め込みモデルにより獲得されます。
話者埋め込みモデルについてはGoogleが提案しているGE2Eと呼ばれる手法[2]を用いています。
以下は上記の話者埋め込みの手法についての解説のサイトです。
google.github.io
学習フローについて
論文の通りの学習では、以下のフローで学習を行います。
- Tacotron2の学習:TTL-VC Decoderの重み初期値 + Context Vectorの作成のため
- Decoder Adaptation Process:(4)式を用いてDecoderのみを学習
- TTL-VCの学習:Encoder, Decoderをend2endで学習
ですが、自分の環境では上記のフローでは学習が上手くいかなかったので、以下のフローで学習を行いました。(発生した現象や問題点の詳細・考察に関しては所感の項目に記載しています)
- Tacotron2の学習:TTL-VC Decoderの重み初期値 + Context Vectorの作成のため
- Encoderの事前学習:MelSpectrogram → Context Vector の変換を事前学習
- Decoderの学習:Context Vector → MelSpectrogram の変換を学習、この時Encoderの重みはfreezeさせる
ここで、Encoderの事前学習時に用いるContext Vectorは事前に学習したTacotron2を用いて事前に生成し、Decoderの学習時に用いるContext Vectorは直前に学習したDncoderを用いて生成しました。
実験
実験では、3つのベースライン手法と提案手法の品質比較を行っています。
以下は、ベースライン手法と提案手法の学習の条件や制約について比較をした表です。

ベースライン手法についての簡単な説明です。
MS-TTS
- Malti-Speaker TTSの略で、実験ではTacotron2を学習モデルとして用いています。他のベースライン手法と異なり、MS-TTSはTTSタスクを学習し、テキストから生成された音声を生成音声として用います。
- MS-TTSは、生成された音声の品質に関する比較評価のために用意されたベースライン手法です。
PPG-VC
- PPG-VCのモデルは、ASR(Automatic Speech Recognition、音声認識)を行うEncoderと、音素列から音響特徴を復元するDecoderで構成されています。
- EncoderはKaldi toolkitsを用いて、MFCCからPPG(Phonetic PosteriorGram、音素事後確率)と呼ばれる、フレーム毎の音素のベクトル確率表現を予測するように学習を行います。(フレームシフト:12.5 ms、MFCC:40次元)
- Decoderの構造は、Tacotron2のデコーダとほぼ同じ構造で、PPGフレームを入力として受け取り、80次元のMelSpectrogramを予測するように学習を行います。
- PPG-VCは、TTL-VCと似たEncoder、Decoderの構造をしているため、ベースライン手法として採用されています。また、PPGベースのVC手法は、近年のVCタスクにおいて最先端の性能を発揮することが知られています。
VAE-VC
- VAE-VC はTTL-VCに非常によく似ていますが、潜在空間が平均と分散により表現される点、
が制約として与えられない点が大きな違いとなります。
- VAE-VCのEncoderは、LSTM layerに続いて2つのFull Connected Layerが接続されており、それぞれ平均ベクトルとガウス確率分布の対数分散ベクトルを出力します。最終的なEncoderの出力はReparameterization Trickにより確率分布からサンプリングされます。
- VAE-VCのDecoderはTacotron2やPPG-VCのDecoderと似ていますが、他の手法と異なり自己回帰構造を用いることなくフレームごとのマッピングを学習します。そのため、モデル内部にAttention Mechanismを持ちません。
- TTL-VCとVAE-VCの最も大きな違いは、転移学習の有無にあります。VAE-VCは、転移学習によりTTSの知識伝達が得られるTTL-VCとの比較のために用意された手法です。
結果
以下は、作者が公開している本手法のデモ音声が聴けるサイトです。
demo : https://arkhamimp.github.io/TTL-VC/
品質の確認の際はデモを聞くことをお勧めします。
以下は実験の結果を示す図になります。



図1、図2は提案手法と各ベースライン手法の生成音声のどちらが高品質な音声を変換できているかというアンケートの比較結果です。オレンジが提案手法、青が比較対象となるベースライン手法となっています。
また、図3において、提案手法のMOSの値はMS-TTSとほぼ同等ということがわかります。
上記より、TTL-VCは既存のVCまた、MS-TTSはTTSタスクにおける手法なので、TTL-VCはTTSモデルと同等の品質の音声へと変換することが可能であると言うことが確認できました。
また、以下は手法ごとのMCDとRMSEに関する実験結果です。

のRMSE
ここで、MCDとRMSEの定義は以下の通りです。


MCD(mel-cepstrum distortion)は、変換の前後で音響特徴であるmel-cepstral coefficients (MCCs) がどれだけ変化したかを表す指標です。
RMSE(root mean square errors of
)は、変換音声と目標音声のフレーム毎の
の差を表す指標です。(目標音声はDTWにより整形されています)
どちらも、値が小さければ小さいほど目標話者との解離が少なく、生成音声の分布がであるという指標となります。
所感
音声変換において、話者性を完全に排除した埋め込み表現を得ることは非常に難しく、現在も様々なアプローチによって検証がなされています。 この手法ではTacotron2の文章埋め込み情報をVCタスクへと使用するというアプローチを用いており、完全に話者性を排除でき、さらにDecoderにより音声を生成することがTTSタスクの事前学習によりある程度保証されるので、個人的にはとても良いアプローチだなと思いました。
逆に、この手法のWeekpointは以下の点かなと思いました。
Encoderを汎化させるために、大規模なTTSコーパスを用いた事前学習が必要。英語のコーパスであればlibrittsを用いれば良いので良いが、他の言語(特に日本語)での学習はコーパスを用意する必要があり、敷居が高い。
TTL-VCの学習の際、Encoderの重みを全てfreezeしないと、話者埋め込みが全く機能しなくなってしまう問題。
- 論文に記載がなかったのですが、自分の環境で学習を行った際、EncoderとDecoderを同時に学習させた場合、生成される音声が(話者埋め込みが何であれ)入力音声と全く同じになってしまうという現象が発生しました。
- 上記の問題に関して、自分は「EncoderにMelSpectrogramのlossが伝播されてしまうと、話者性に関する情報を埋め込むようになってしまうのではないか?」という仮説を立て、Encoderの重みを完全にfreezeさせて学習を行った結果、上手く音声を生成できるようになりました。
Context Vectorにはイントネーションの情報は含まれないので、生成される音声のイントネーションと入力話者のイントネーションの解離が生じてしまう。
総じて、改善次第でとても有用性のある良いアプローチだなと思いました。
参考文献
論文解説:Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining
目次
論文情報
arxiv:[1912.06813] Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining
demo : Voice Transformer Network: Sequence-to Sequence Voice Conversion using Transformer with Text-to-Speech Pretraining
概要
本手法では、TTS(text-to-speech)タスクによる事前学習を用いた、Transformerベースの1対1seq2seq音声変換モデルを提案しています。
音声変換タスクにおいて、RNNやCNNをベースとしたseq2seqモデルは多く提案されていますが、自然言語の分野で用いられることの多いTransformerをベースとした音声変換の手法は未だ提案されていません。
加えて、現状seq2seqモデルを音声変換タスクに用いること自体、学習に必要なデータ量が非常に多いことや変換された音声の品質が悪いことから、実用には程遠いと言えます。
本研究では、大規模かつ利用しやすいTTSコーパスを利用して学習を行ったTTSモデルから、音声変換タスクへと知識を伝達する学習手法を提案しています。
事前学習されたモデルパラメータを用いて初期化された音声変換モデルは、高忠実度で明瞭度の高い音声の隠れ表現を生成することが可能としています。
結果として、提案する学習手法がデータ効率の良い学習を促進し、明瞭度、自然性、類似性の点で既存のseq2seq音声変換モデルよりも優れていることを示しました。
提案手法
本手法では、TTSタスクから音声変換タスクへ転移学習を行う学習手法と、そのモデルであるVoice Transformer Networkを提案しています。
以下では、TTSの枠組みであるseq2seq TTSの簡単な解説を行った後、本手法の解説をします。
sequence-to-sequence TTS
seq2seqのTTSでは入力特徴列 から、目標特徴列
を生成します。
RNNやLSTMベースの手法では入力と出力の系列長が一致する必要がありましたが、seq2seqの場合は必ずしも両者の系列長が一致している必要はありません。
(i.e, )
seq2seqのモデルの多くはエンコーダ・デコーダ構造となっており、近年の研究ではattention機構が組み込まれたモデルが提案されています。
エンコーダにより、入力として与えられた が隠れ表現
にマップされます。
またデコーダは自己回帰的に
を生成します。
の重み付きベクトル和がcontextベクトル
として計算されます。
ここで、重みは注意確率ベクトル
として表現されます。
注意確率ベクトルのそれぞれの要素
は、隠れ表現
の時刻tにおける重要度を表していると考えることができます。
デコーダはcontextベクトル
と時刻t-1までに生成された特徴列
を用いて、
を生成します。
注意確率ベクトル
の計算、デコーダの生成にはデコーダの隠れ状態
もインプットとして与えれられます。
以上の処理を定式化すると以下のようになります。
TTSと音声変換のタスクは(特にデコーダの処理内容が)似ているため、転移学習的なアプローチを行えないだろうか?というのが本研究のテーマとなります。
Transformer-based TTS
本手法では、自然言語処理の文脈で猛威を奮っているTransformer[3]をベースとしたモデルを用いています。
多くの方が解説記事を書いてくださっているため、ここではTransformer自体に関しての解説はしません。
自分が日本語の解説記事を読んでいた際は、こちらの方の記事がとても参考になりました。
deeplearning.hatenablog.com
以下では、本手法で提案しているVoice Transformer Networkと、そのベースモデルであるTransformer-TTSについて解説します。

上記はTransformer-TTSとVoice Transformer Networkの概要図です。
Transformer-TTSは、TransformerにTacotron2のアーキテクチャを結合したような構造となっています。
Transformerとの変更点として、エンコーダ側とデコーダ側にTacotron2由来のPre Netが追加されています。
また、TTSタスクの入力であるテキスト系列とVCタスクの入力であるスペクトログラムでは空間のスケールが異なるため、学習可能な重みを持つ位置埋め込み(Scaled Positional Encodings)を導入しています。
出力側では、音響特徴量を生成するための線形投影と、ストップトークンを予測するための線形投影のためのレイヤが追加されています。
また、最近年提案されているTTSモデルの多くで、5層のCNNで構成されるPost Netで残差を予測し、最終出力に足し合わせることで品質を高めるという手法を用いており、本手法においても同様のアーキテクチャを採用しています。
本手法ではこのアーキテクチャを用いてTTSタスクの学習を行い、転移学習として音声変換タスクを学習します。
学習について
本項では、本手法の学習について解説します。

上記はVoice Transformer Networkの一連の学習フローの概要図です。
学習で用いるデータセットについてですが、小規模のパラレル音声コーパス、そして大規模なTTSコーパス
がそれぞれ使用可能であるとします。
ここで、はそれぞれソース、ターゲット話者の音声を指し、
はそれぞれTTSコーパスのテキストと音声を指します。
本手法では、を第一段階の事前学習に、
を第二段階の適応学習に用います。
Decoder pretraining
まず、を用いてTransformer-TTSを普通に学習します。
このフェーズで、音韻情報が押し込まれた隠れ特徴空間から音声を生成するデコーダ
が学習されます。
Encoder pretraining
次に、Decoder pretrainingで学習したを用いて、エンコーダ
を学習します。
この時、
の重みはフリーズします。
のアーキテクチャですが、入力が音声
となるため、Transformer-TTS(VC)の概要の図で示した[VC]のアーキテクチャを用います。
このフェーズで、は音声の音韻情報のみを効果的に隠れ特徴空間
へと押し込むように学習されます。
VC model training
最後に、Decoder pretrainingで学習したと、Encoder pretrainingで学習した
の重みで
と
初期化し、
を用いて学習を行います。
既に事前の学習で音声変換タスクに対して非常に適応しやすい重みを獲得しているため、スクラッチから学習を行う場合と比較して半分の時間で学習が収束するとしています。
実験
本論文では、転移学習の効果を比較するための実験と、ベースラインとの品質の比較をするための実験の2つの実験を行っています。
転移学習の効果を比較するための実験では、異なるサイズの教師データを用いて学習した場合の品質比較、またデコーダとエンコーダの事前学習を行わなかった場合の品質比較を行っています。
ここでの教師データというのはVC model trainingに用いるパラレルの音声データのことを指しており、事前学習では大規模なTTSコーパスを用いて学習していると考えられます。
ベースラインとの品質の比較をするための実験では、ATTS2S[5]というTacotronベースの手法との品質比較を行っています。
実験条件はATTS2Sとほぼ同様ですが、本手法では変換にメルスペクトログラムを用いています。(ATTS2SではWORLD特徴量を用いています)
比較では、生成された音声の自然性と話者一致性に関しての評価を比較しています。
結果
以下は、作者が公開している本手法のデモ音声が聴けるサイトです。
demo : Voice Transformer Network: Sequence-to Sequence Voice Conversion using Transformer with Text-to-Speech Pretraining
品質の確認の際はデモを聞くことをお勧めします。
以下は、転移学習の効果を比較するための実験の結果を示した表です。

教師データが少ない場合でも、ベースラインであるATTS2Sよりも高い品質の音声が生成できていることがわかります。
また、エンコーダとデコーダの事前学習が最終的な品質に大きく影響を与えていることが確認できます。
また、以下はベースラインとの品質の比較をするための実験における、ベースライン手法であるATTS2Sと提案手法(VTN)の比較表です。

提案手法がベースラインに比べて高い自然性と話者一致性を示していることがわかります。 また、教師データのサイズが非常に小規模な場合(80)においても、非常に高い自然性と話者一致性を維持していることも確認できました。
所感
この論文が公開された当初はどうだったのかわからないですが、最近ではTTSで学習したモデルを音声変換のデコーダとして用いる、もしくは転移学習により音声変換タスクに利用するという手法がそこそこ提案されていて、流行を感じます。[4]
これらの手法は、音声変換のネックとなっていた「どのようにして音声から話者性を消して、新しい話者性に上書きするか」という問題に対して、事前にテキスト→音声で学習済みのモデルを用意してあげることで、エンコーダにテキスト情報(発話情報)を獲得させることを暗に強制するという解決をしており、個人的にもとても理にかなっているアプローチだなと思っています。
デモに関しても、非常に高品質な音声へと変換ができていると感じます。
元音声の抑揚、イントネーションの情報は失われてしまいますが、それが問題ないようであれば本手法のようなTTSのモデルをVCへと流用するアプローチはとても良いなと思いました。
参考文献
論文解説:AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss
目次
論文情報
arxiv:[1905.05879] AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss
demo : AutoVC Demo https://github.com/auspicious3000/autovc
概要
非並列データを用いた多対多の声質変換において、Zero-Shotの音声変換を可能とする手法を提案。
声質変換分野では、近年はGANが用いられることが多いが、GANの訓練は一般的に難しく、また生成された音声が知覚的に良い品質であることが保証されない。 別のアプローチであるCVAEなどの手法は、学習はシンプルだがGANのような分布一致性を持たない。
本論文では、慎重に設計されたボトルネックを持つAuto Encoderを用いた声質変換手法を提案する。 提案手法であるAUTOVCは、非並列データを用いた多対多の音声変換において最先端の成果を達成し、さらにゼロショット音声変換を世界で初めて実現した。
提案手法
学習について

図1において、は話者の音韻情報と韻律情報を持つcontent distributionsからサンプリングされたランダム過程であり、
は話者集団からサンプリングされた話者のIdentityを持つランダム変数だと定義しています。
は音声分布からサンプリングされたランダム過程であり、
と
により特徴付けられているものであるとしています。
はContent Encoderを、
はDecoderを指し、
は事前学習済の話者埋め込み用モデルを指します。本論文では、参考文献[2]の手法を用いて事前学習されたモデルを用いて、256次元の話者ベクトルを出力しています。
は
によってエンコードされたコンテンツ情報(発話情報)を持つランダム過程であり、
は
によってエンコードされた話者埋め込みベクトルを指します。
実装では、にはスペクトログラムが使用されています。
学習時は、入力話者と目標話者を同じにして学習を行います。一方で、変換を行う際は目標話者から生成した話者ベクトルをの入力として与えることで変換を行います。ここで、
の表現力が十分である場合、未知の話者が目標話者(もしくは入力話者)に現れた場合でも埋め込み話者ベクトルの情報からZeroshotでの変換を行うことが可能となることを期待する、としています。
モデル

)、(b)がStyle Encoder(
)、(c)がDecoder(
)、(d)が Spectrogram Inverter(音声復元モデル)です。
詳細に関しては図や実装を見ればわかるので割愛します。
Loss
学習の目的関数は以下の式の通りです。


は self-reconstruction errorのことで、
と
のMSEをとっています。 self-reconstruction errorは音声がちゃんと再構成されるような制約を与えるためのlossです。
また、はcontent code reconstruction errorのことで、
と
のl1 normをとることで算出されています。content code reconstruction errorは変換された音声の話者性が保たれているような制約を与えるためのlossです。
なぜ学習がうまくいくのか?

から入力される話者性に関する情報が消えて、発話内容(content)だけがうまく獲得される、という趣旨の主張です。
実験
実験では、VCTKコーパス(44時間の発話、男女合わせて109人の話者)を用いて学習を行いました。
また、「話者埋め込みモデルはあくまでもZeroshot(教師データにない話者を入力、もしくは目標話者とする変換)に適用するために用いるのであり、品質には影響を与えない」ということを証明するために、one-hotベクトル表現による話者ベクトルを入力した場合の学習の比較も行なっています。
結果
こちらのサイトでデモが公開されています。
音声変換の結果に関しては実際に聞いてみて判断するのが最もわかりやすいと思います。著者も
We strongly encourage readers to listen to the demos.
とのことです。
以下は、論文中で行われた実験におけるMOSとsimilarity scoreの値の比較表です。(MOS:平均オピニオン評点(mean opinion score, MOS)は品質に関して、similarityは話者性に関しての評価)

また、図5の右2つのグラフは未知の話者と学習データにある話者の品質の差を比較しています。unseenの女性に関しては変換が難しそうですが、これは女性が男性に比べて声色の分布が広いことが起因するのでしょうか。
所感
正直この手法で、なぜ話者性が変換出来ているのかがわかりませんでした。
本当に変換がうまくいくのか試すために、著者の方が公開している実装を元に再現実装を行ない、手元の日本語話者データを用いて再現実験を行ないました。 実装で公開されている話者埋め込みモデルが日本語話者にうまく適用出来なかったようなので、話者埋め込みに関してはone-hot表現を用いました。(論文中でも述べられていましたが、埋め込みモデルはZero-Shotの変換のために用いており、one-hotを用いても品質に差は生じないそうです)
実装は公開出来ないのですが、結果として女性→女性の変換において、デモと同等の品質での変換が確認出来ました。男性を用いた変換はあまりうまくいかなかったのですが、これは用意したデータの偏りの影響であると考えられるため、日本語話者の学習においてもデモと同等の変換結果が得られたと結論付けました。