論文解説:Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
目次
論文情報
arxiv:[2012.01837] Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training
demo : https://hhguo.github.io/DemoEASVC/
概要
本論文では、end-to-endの敵対的歌声変換手法であるEA-SVC(End-to-end Adversarial Singing Voice Conversion)を提案しています。
EA-SVCでは、発生内容を表すPPG(phonetic posterior-gram、音素事後確率)、ピッチを表すF0、音色を表す話者埋め込みの3種類の特徴量から任意の歌声音声波形を直接生成することが可能です。
提案するモデルは、Generator 、Audio Generation Discriminator
、Feature Disentanglement Discriminator
の3つのモジュールから構成されています。
Generator
は入力される3種類の特徴量を並列にエンコードし、それらをconcatした物をデコードすることで目的の波形へと変換します。
さらに、Feature Disentanglement Discriminator
を適用し、Generator
によりエンコードされたPPGに残っているPitchとtimbrerの情報を除去することで、よりロバストで正確な歌声変換を実現することが可能となります。
また、提案手法では訓練を2段階に分けて行っており、これにより安定した効果的な敵対者訓練プロセスを維持することが可能となります。
実験より、提案モデルは品質と話者類似性の両方において従来のcascadeな畳み込みの手法とWaveNetベースのend-to-endの手法を凌駕していることが確認できました。
また客観分析では、提案する2段階の訓練により学習したモデルはより滑らかでシャープなフォルマントを生成し、高品質化な生成が可能になることが明らかになりました。
提案手法
本論文では、end-to-endの敵対的歌声変換手法であるEA-SVCを提案しています。
本論文のContributionsとして、以下のことが挙げられます。
波形にPPG、F0、話者埋め込みをマッピングするために、MelGAN[2]をベースにしたジェネレータを設計しています。
入力特徴量を波形に変換する際に、CNN-BLSTMベースのモジュールにより、PPGとF0シーケンスからそれぞれの特徴量を抽出し、concatしています。 また、ロバストで制御可能な音色表現を獲得するため、話者埋め込みは異なる音色・話者を表す訓練可能なベクトルの重み付け和として表現されます。2つの識別器がGenerator
の学習プロセスに追加されます。
Audio Generation Discriminatorは、本物の音声と生成された偽の音声を分類することで、より良い品質の音声を生成できるようにGenerator
はエンコードされたPPGの情報からピッチ情報と音色情報を推測するような学習を行い、Generator
上記学習プロセスを効率的かつ安定的に行うために、2段階の学習戦略を採用しています。
提案手法では、まずmulti-resolution STFT(MR-STFT) Lossを用いて生成器を訓練し、その後モデルをより安定させるためにMR-STFT Lossと敵対的Lossの両方を用いてモデルを訓練します。手法の評価のために、主観試験と実験分析を実施しています。
MOSによる評価の結果、提案手法の有効性が実証されました。 提案手法は従来のcascadeな畳み込みの手法やWaveNetベースのend-to-endの手法に比べて品質と話者類似度の両方において優れた性能を示したました。 客観分析では、提案する2段階の訓練により学習したモデルはより滑らかでシャープなフォルマントを生成し、高品質化な生成が可能になることが明らかになりました。 さらに、提案手法の有効性を検証するために、提案モデルを用いて音色やピッチの制御実験を行いました。
Generator
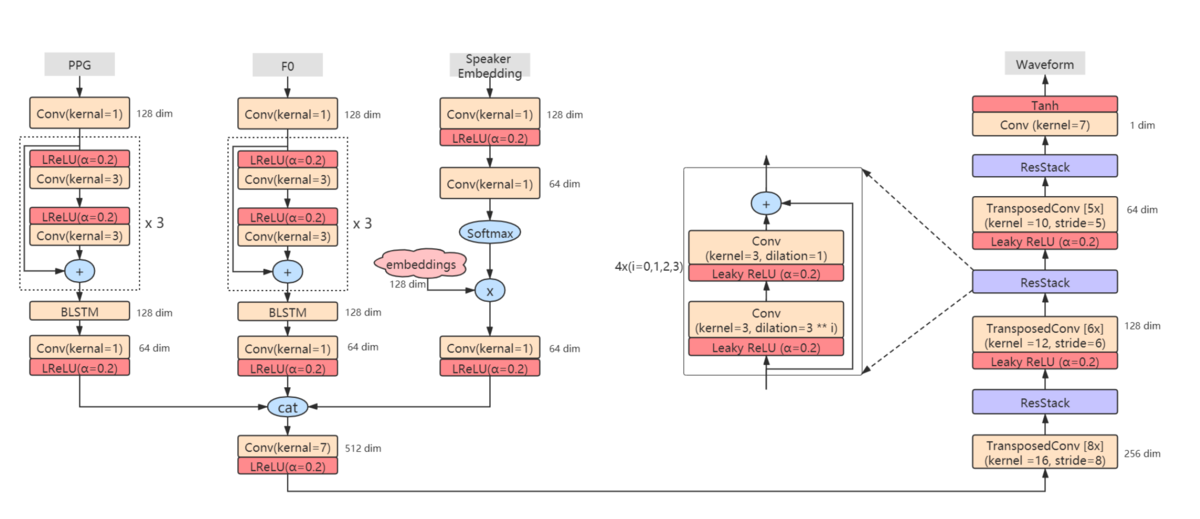
のアーキテクチャ
は、上記の概要図の左側と右側でそれぞれ別の役割を持っています。
図の左側のモジュールはEncoderとしての役割を担っています。入力としてPPG、F0、話者埋め込みベクトルのsequentialな情報を受け取り、並行して情報の圧縮を行います。
ここで、より良い話者埋め込み表現を獲得するため、GST-Tacotron[3]で提案された話者埋め込み手法にinspiredされた話者埋め込みのモジュールを提案しています。 以下が提案している話者埋め込みのモジュールを表す式となります。
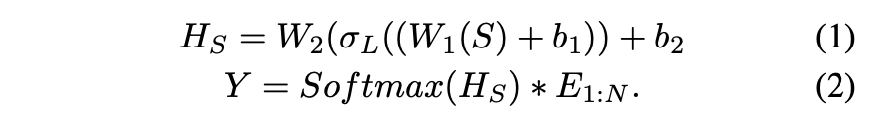
は非線形変換がなされた入力話者ベクトルを、
はtrainable weight vectorを表しています。
直接 を用いるのではなく、
を用いて
のweightを学習することで、clusteringもしくはdisentanglementを促すことができるという主張です。(詳細に関しては自分もまだ理解出来ていません)
図の右側のモジュールはUpsamplerとしての役割を担っています。Encoderにより圧縮された特徴量から、音声波形を直接生成します。
Upsamplerモジュールの構造はMelGAN[2]に非常によく似ており、またLossに関してもMelGANと同じmulti-resolution STFT Loss を用いています。
以下はSTFT Lossの定義を示す式となります。
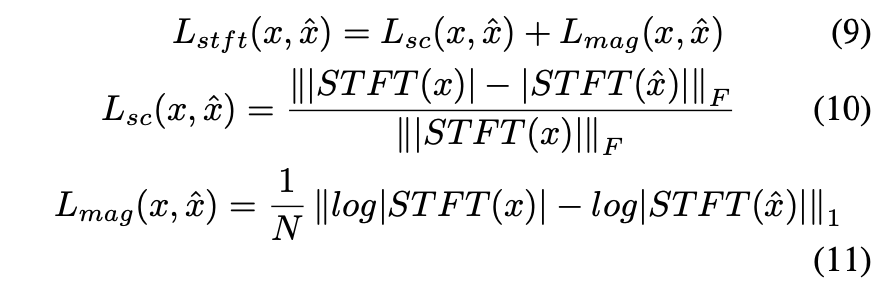
はspectral convergence Loss、
はlog STFT magnitude Lossを表し、それぞれスペクトル領域での周波数の割合と大きさについての差分を計算するようなLossとなっています。
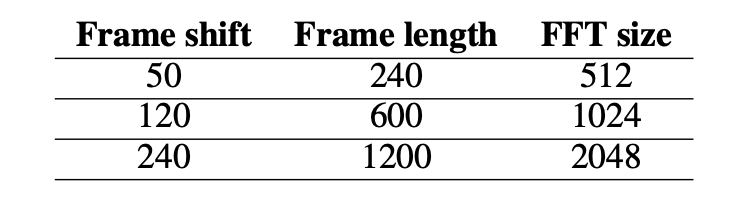
multi-resolution STFT Loss では、STFT Lossを複数の解像度で計算し、そのsumをとることで計算されます。論文では以下の表のパラメタを用いています。
後述する と
からのadversarial lossと上記をまとめると、
に対するLossは以下のようになります。
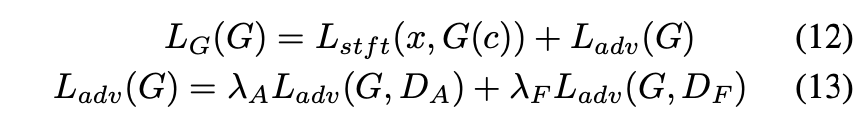
Audio Generation Discriminator

のアーキテクチャ
は、入力された音声がオリジナルの音声なのか、Generator
により生成された音声なのかを識別するような学習を行います。
を騙せるように
の学習を行うことで、
の生成する音声の品質を高めるのが狙いです。
に対するLossは以下のようになります。
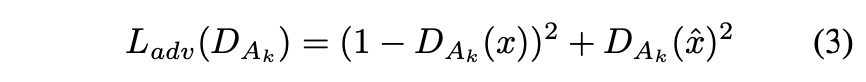
に対しては、通常のAdversarial Lossに加えて、以下の式で定義されるFeature Mapping Loss
を与えます。
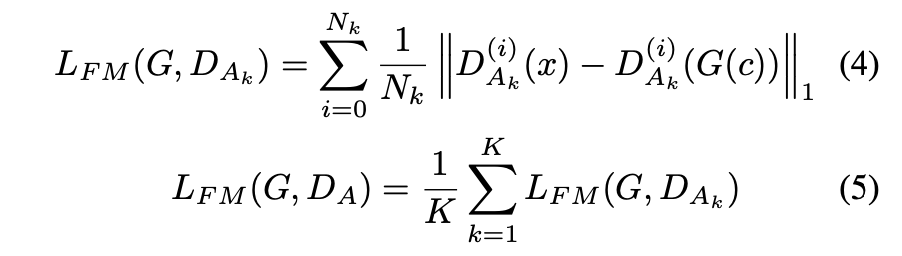
はオリジナルの音声が入力された場合と
により生成された音声が入力された際に、
のブロック
ごとの出力が同じになるような制約を
に与えています。この制約により、
が
の各特徴空間レベルでオリジナルの音声に似ている音声を生成できるように促します。
最終的に により与えられる
に対するLossは以下のようになります。
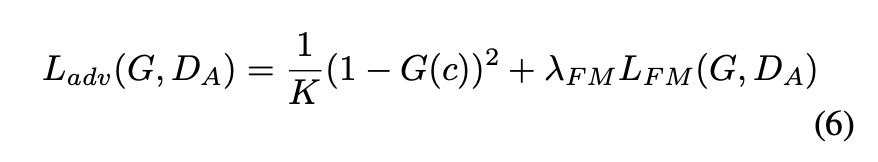
Feature Disentanglement Discriminator
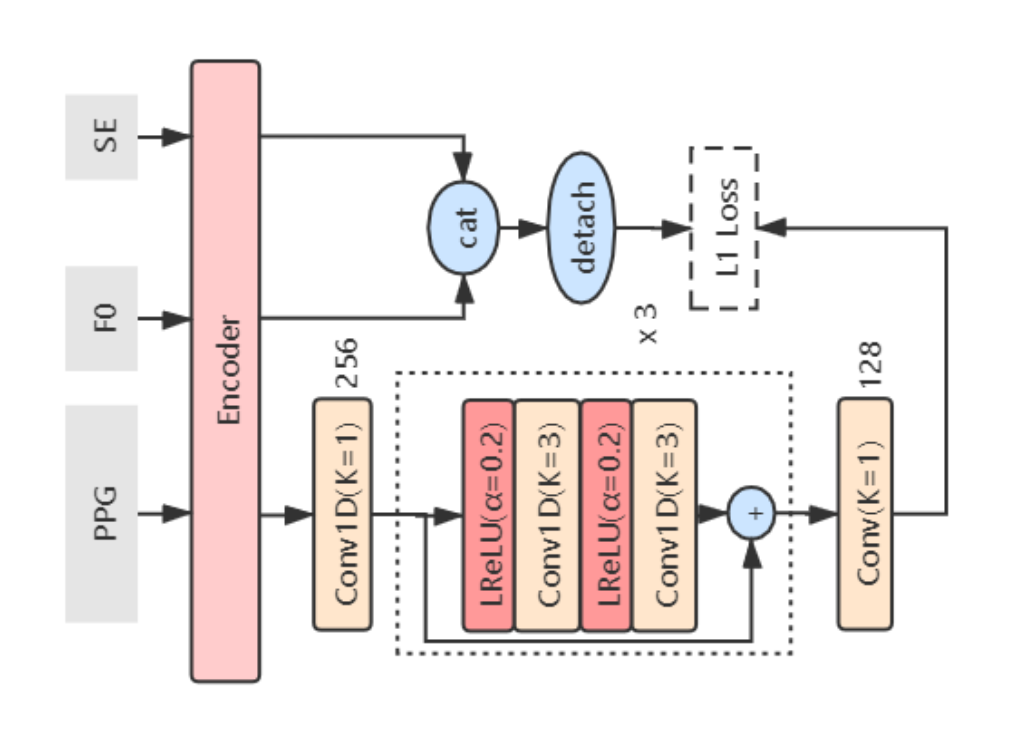
のアーキテクチャ
は、敵対的学習によりGenerator
によりエンコードされたPPGからF0と話者性に関する情報を除去するためのモジュールです。
PPGはコンテンツ情報をよく表現する一方で、音程や話者性の情報を含んでしまうことが知られており、モデルがその情報に依存してしまうと情報の衝突が発生しノイズの原因となってしまいます。
は、Generator
によりエンコードされたPPGから、同じくエンコードされたF0と話者埋め込み情報がconcatされた値を予測するように学習を行い、
にはそれを妨げるように制約を与えます。
ここで、 に対するLossは以下のようになります。
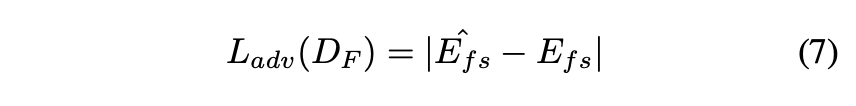
また、 を用いた
に対するLossは以下のようになります。
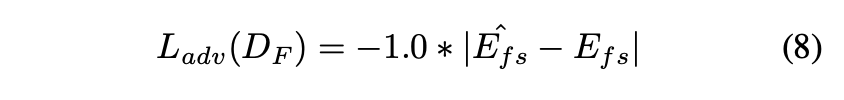
2段階の訓練
Generator 、Audio Generation Discriminator
、Feature Disentanglement Discriminator
の3つのモジュールを効率的に、安定して学習させるために、提案手法では学習を2つの段階に分けて行うアプローチを提案しています。
Stage 1では、 のみを学習させます。Lossは
のみを用います。
ここでの目的は、 が学習により入力特徴量と音声波形間の正確で安定したマッピングを獲得することです。これにより、
により安定した生成が行われることが保証されます。
Stage 2では、 、
、
の全てのモジュールを学習させます。Lossは全て用います。
ここでの目的は、Stage 1で学習した
のweightを、より最適な分布へと近づけることです。
実験
実験では、従来のcascadeアプローチの手法・WaveNetベースの手法と提案手法のMOS比較を行っています。
cascadeアプローチには、EA-SVCににたモデルを用意しています。違いとして、f0やspk_embを用いていないこと、生成対象がメルスペクトログラムであることが挙げられます。生成されたメルスペクトログラムは、学習済のMelGANを用いて音声波形へと変換します。
WaveNetベースのアプローチには、NVIDIAが以下のリポジトリで公開しているend-to-endの歌声変換モデルを用いています。
GitHub - NVIDIA/nv-wavenet: Reference implementation of real-time autoregressive wavenet inference
また、 、
の効果を検証するための
と
の有無による生成音声の比較実験、2段階の訓練を行う事による生成音声の比較実験、生成音声の制御性検証のためのピッチコントロール・話者性のコントロール実験についても追加で行っています。
結果
以下は、作者が公開している本手法のデモ音声が聴けるサイトです。
demo : https://hhguo.github.io/DemoEASVC/
以下は従来のcascadeアプローチの手法・WaveNetベースの手法と提案手法のMOS比較の結果を示す表になります。
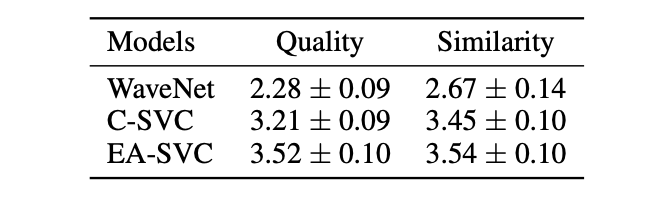
提案手法のMOSが優れていることが確認出来ます。
以下は、 と
の有無による品質と話者類似性の比較実験の結果を示す表になります。
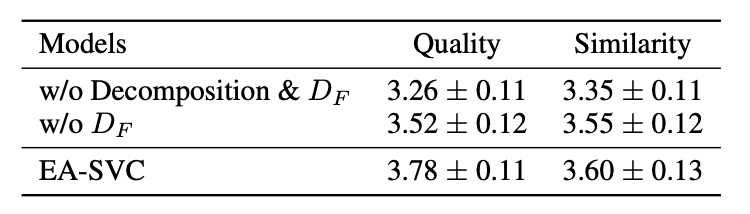
と
の有無による比較実験の結果
と
が品質に強く影響を与えていることが確認出来ます。
以下は2段階の訓練を行うことで、生成される音声のスペクトログラムにどのような差が生じるかの検証実験の結果を示す図になります。
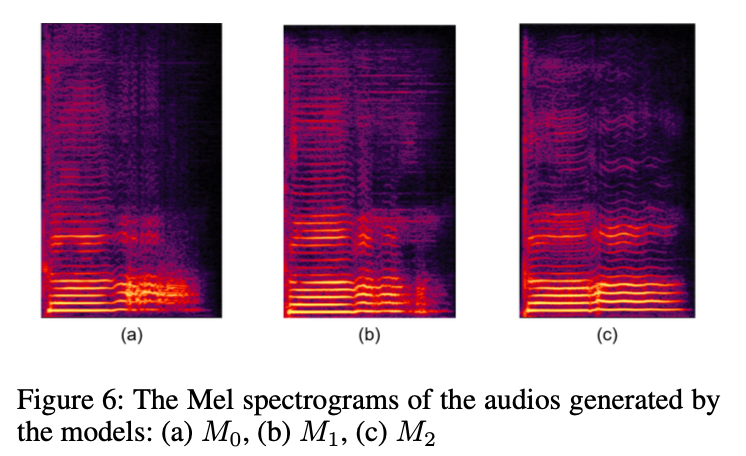
、
、
はそれぞれ以下のような設定で学習したものになります。
:Stage2のみの学習、
のみで学習。
:Stage2のみの学習、
)で学習
:Stage1+Stage2を段階的に学習、
がもっとも明瞭で滑らかなスペクトログラムであることが確認出来ます。
以下は、話者性を逐次的に変化させて行った際のaveraged magnitude spectrogramを示した図になります。
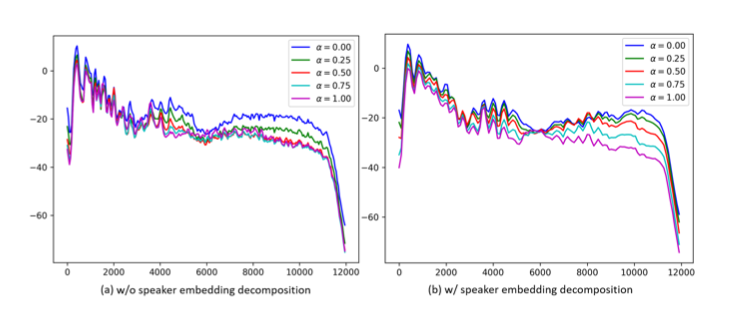
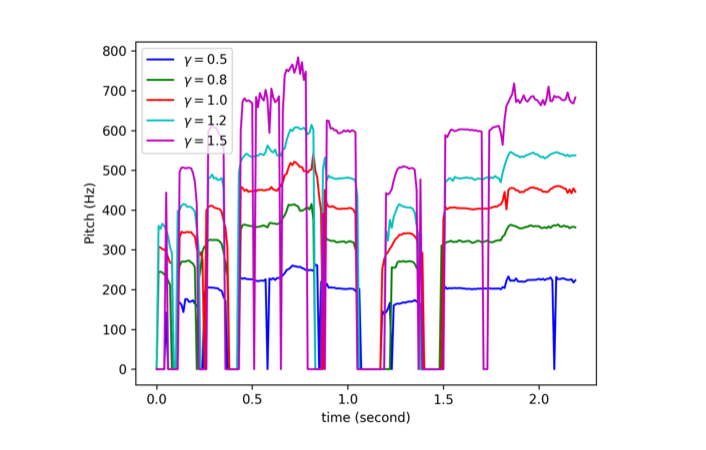
所感
最近の音声変換手法はPPGを使うアプローチが頭ひとつ抜けて品質が良い印象があります。
また、MelGAN[2]は学習が安定すること、生成音声の品質が良いこと、推論が従来のNeuralVocoderと比較して早いことなどから個人的に好きな手法だったので、MelGANのアーキテクチャをベースにしたEA-SVCのモデルアーキテクチャはかなり良いなと思いました。